Snapshot Serengeti is a citizen science project that invites volunteers to identify animals in previously unseen automated camera trap images. Users will annotate the images, with species present, number of animals, and also what behaviours they currently perform. The linked Talk application also allows user to add hashtags, write comments and have discussions about those images as shown to the right.
One of MICO’s goals is to support Zooniverse in more easily gaining insights into the images by performing content analysis on the images and comments. This blog post focuses on a specific aspect of this use case – the detection of the competence, or skill level, of a user by analysing that user’s comments. This involves distinguishing comments that are questions or opinions from others that provide facts, feedback and clarifications.
This blog post describes how competence classification of Snapshot Serengeti user comments was realised in the MICO project. The first section focuses on the dataset used and how it was processed and visualizes to establish the heuristics used train the competence classification. The second section describes the heuristics used to classify user comments, how the training set was created and the OpenNLP Document Categorizer model was trained. The final section describes how document categorisation is supported by the MICO Platform and how to use the model trained for competence classification. It also provides an example of a competence classification request to the platform and a sample response.
Serengeti Snapshot User Comments Data
For the training of a competence classification we extracted a (denormalized) view over the Snapshot Serengeti user data with about 100,000 entries, each containing the following fields:
- userID – this allows the user to be uniquely identified, and that user’s comments to be collected together.
- number of images annotated by this user – this defines how active a user is
- percentage [0..1] of correctly annotated images – this gives a good estimate about the expertise of the user, especially for very active users. This is less useful for users with very few annotated images. (Most Snapshot Serengeti users leave few or no comments)
- user comment – the body of the user comment itself
Typically when you train a categorisation model what you start with is the ground truth. You would select a sub-set of the 100,000 comments and manually classify each comment according to your defined categories. However for this use case the decision was made to skip this manual process and try to create the training set by using heuristics to reason about the provided data.
For establishing those heuristics the data was first imported into Open Refine as this tool provides a powerful means to clean, filter, facet and visualize data.
The following screenshot of Google Refine (as Open Refine was previously known) shows the facets used to analyse and filter the Snapshot Serengeti data.
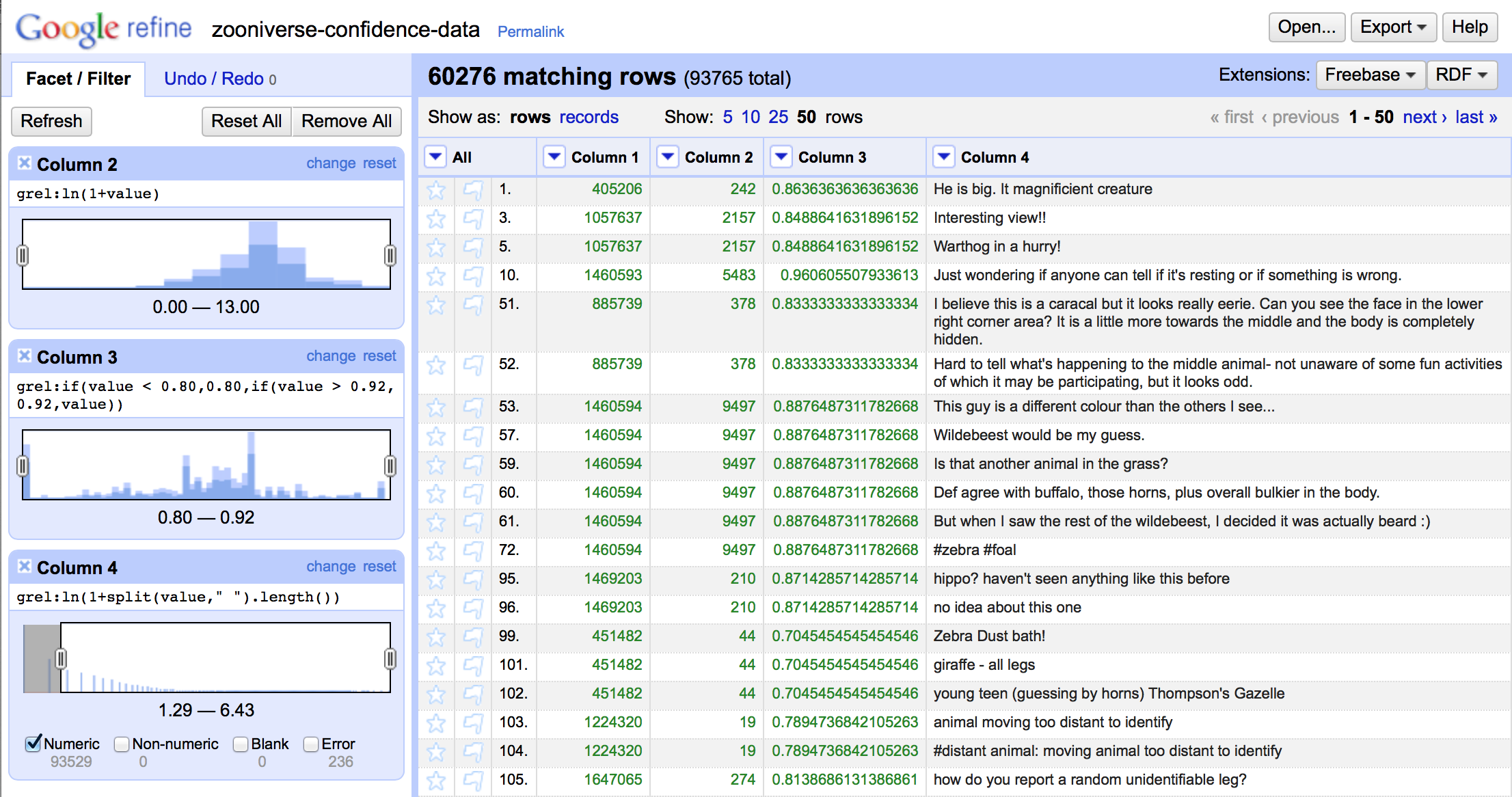
The chosen facets are:
- Logarithmic scale view showing the number of annotated images. A logarithmic scale provides a much nicer distribution over the activity levels of different users.
- Facet by the percentage of correctly annotated images. As most values are in the area between `0.8` and `0.92` this facet is configured to sum up all values `<= 0.8` and `>= 0.92`.
- A Logarithmic scale faceted by the number of words of the comments. This facet nicely shows the the length of comments has a logarithmic distribution.
Note that Open Refine allows us to define filters over facets. The above screenshot shows such a filter over the third facet (over column 4) that excludes all comments with less as three words. Rows not matching the currently defined filters are not shown in the list. This feature is critical for the definition of heuristics and the validation of the same.
Establishing the Heuristics for the Training Set
Filtering empty and short user comments
For this we can apply a filter on the third facet. Such a filter is actually shown in the above figure. Empty comments are shown as errors and comments with less as three words are represented by values `<= ln(1+2) = 1.099`. So the filter `[1.29 – *]` as shown in the figure will include all comments with 3 or more words.
As the figure shows, there are about 60,000 user comments with 3 or more words. When looking at the other two facets one can also see lighter and darker blue sections in those facets. The lighter blue area represents filtered rows while the darker blue represents the percentage of none filtered rows. The fact that the percentage of lighter and darker blue areas is about evenly distributed over the whole area of the other two sections indicates that the length of the text does not provide an indication of the competency of a comment.
Defining low and high competency
For creating a training set we need to define competency levels to rows in the provided dataset. To make things easier the decision was to go with only two categories:
- COMP (competent)
- INCOMP (incompetent)
Assignment of dataset rows to those categories is based on rules using the following definitions:
ln-anno-img:=ln(1+{column2}): logarithm over the number of annotated imagescor-anno:=column3: percentage of correctly annotated imagesq-words:= A list of words indicating a question (`?`, `who`, `what`, `why`, `may`, `can't`, `can not`)
Global:
- Rule 1: only comments with
>= 3tokens are considered
INCOMP Rules
- Rule 2: `
ln-anno-img >= 2` and `ln-anno-img <= 5` — Comments of Users that have only some annotated Images are considered as incompetent. - Rule 3: `
ln-anno-img > 5` and `cor-anno < 0.82` — Comments of Users ~100 or more annotated images but a low percentage of correctly annotated images are considered as incompetent. - Rule 4: `
ln-anno-img > 5` and `ln-anno-img <= 9` and `cor-anno >= 0.82` and `cor-anno <= 0.85` and contains `q-words` — Comments of users with an average amount of annotated images and an average percentage of correctly annotated images are considered incompetent if they contain any word indicating a question.
COMP Rules
- Rule 5: `
ln-anno-img < 2` and `cor-anno > 0.9` — The data indicate that their are some expert users that have no or only very few annotated images. This rule correctly select those. - Rule 6: `
ln-anno-img > 7` and `cor-anno > 0.9` — Comments of experienced users with a high percentage of correctly annotated users are considered competent - Rule 7: `
ln-anno-img > 9` and `cor-anno > 0.85` and contains no `q-words` — Comments of very active users with an average to high number of correctly annotated images are considered as competent if they do not contain any word indicating a question.
Applying those Rules to the Data Set
When applying the above rules to the Snapshot Serengeti user comments one obtains the following statistics:
> category: null (count: 67396) - rule: Rule 0: 'no matching rule' (count: 39806) - rule: Rule 1: '< 3 tokens' (count: 27590) > category: COMP (count: 14791) - rule: Rule 7: 'active users comment without query word' (count: 11965) - rule: Rule 6: 'high percentage of correctly annotated' (count: 2669) - rule: Rule 5: 'expert user' (count: 157) > category: INCOMP (count: 11212) - rule: Rule 3: 'low percentage of correctly annotated' (count: 6288) - rule: Rule 4: 'average users comment with query word' (count: 2471) - rule: Rule 2: 'inexperienced user' (count: 2453)
So with the above rules one can create a training set with ~15k comments classified as competent and 11k comments classified as incompetent. About 67k comments are not classified either because they are to short (~28k comments) or they do not fall into any of the regions selected by the above rules (~40k comments).
Training of the OpenNLP Document Categorizer model
For competence classification the OpenNLP Doccat functionality was used. For the training of such models one needs to create a text file where each line represents a training example. The first token of the line is the name of the category (COMP or INCOMP). The remainder of the line is the content. The following listing shows the first 4 lines of the trainings set created by applying the rules defined in the previous sections onto the Serengeti Snapshot user comments data.
INCOMP Just wondering if anyone can tell if it's resting or if something is wrong. INCOMP I believe this is a caracal but it looks really eerie. Can you see the face in the lower right corner area? It is a little more towards the middle and the body is completely hidden. INCOMP Hard to tell what's happening to the middle animal- not unaware of some fun activities of which it may be participating, but it looks odd. COMP This guy is a different colour than the others I see...
Using this file one can train a Doccat model by using
String lang = "en"; //the comments are in English File trainingDataFile = null; //the file with the trainings data int iterations = 1000; //the (max) number of iterations int cutoff = 5; //the cutoff value ObjectStream<DocumentSample> samples = new DocumentSampleStream( new PlainTextByLineStream(new MarkableFileInputStreamFactory( trainingDataFile),charset)); TrainingParameters params = new TrainingParameters(); params.put(CUTOFF_PARAM, String.valueOf(cutoff)); params.put(ITERATIONS_PARAM, String.valueOf(iterations)); DoccatFactory factory = new DoccatFactory(); DoccatModel model = DocumentCategorizerME.train(lang, samples,params,factory); sampleStream.close(); OutputStream out = new FileOutputStream(modelFile); model.serialize(out); out.close();
Wrapping this code with a command line utility one can easily train OpenNLP Doccat models.
For training the Doccat model for the Competence Classifier iterations where set to 10000. Training completed with
10000: ... loglikelihood=-8606.006778391655 0.8514399205561073
Content Classification in MICO
OpenNLP Classification Extractor
With version 2 of the MICO Platform a new Content Classification Extractor will be introduced.
This extractor will search processed items for a text/plain asset and classify its content by using the configured OpenNLP Doccat model. In addition this extractor can be configured with a SKOS thesaurus that allows to map the String categories used by the Doccat model to SKOS concepts defined in the thesaurus. This mapping is done based on values of the skos:notation property.
For the competence classification this Extractor will be configured with the OpenNLP Doccat model trained as described in the previous section. For mapping the categories to a thesaurus the following SKOS Thesaurus was defined:
@prefix cc: <https://www.mico-project.eu/ns/compclass/1.0/schema#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
cc:CompetenceClassificationScheme a skos:ConceptScheme;
rdfs:label "Competence Classification Scheme"@en.
cc:Competent a skos:Concept;
skos:inScheme cc:CompetenceClassificationScheme;
skos:notation "COMP";
skos:prefLabel "Competent"@en, "Kompetent"@de.
cc:Incompetent a skos:Concept;
skos:inScheme cc:CompetenceClassificationScheme;
skos:notation "INCOMP";
skos:prefLabel "Incompetent"@en, "Inkompetent"@de.
Note the skos:notation "COMP" and skos:notation "INCOMP" as those provide the mappings of the two categories trained in the OpenNLP Doccat model with the SKOS concepts defined in the thesaurus.
Content Classification Annotations
Text annotations in Mico are based on the Fusepool Annotation Model (FAM). Therefore Content Classifications in MICO follow the Topic Classification scheme as defined by the FAM.
The following listing shows the annotations for a competence classification of the text
Just wondering if anyone can tell if it's resting or if something is wrong
as created by the OpenNLP Classification Extractor:
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix dc: dc: <http://purl.org/dc/elements/1.1/> . @prefix fam: <http://vocab.fusepool.info/fam#> . @prefix mmm: <https://www.mico-project.eu/ns/mmm/2.0/schema#> . @prefix oa: <http://www.w3.org/ns/oa#> . @prefox compclass: <https://www.mico-project.eu/ns/compclass/1.0/schema#> . @prefix example: <http://www.example.org/mico/competenceClassification#> . test:topic-classification-1 a fam:TopicClassification ; fam:classification-scheme compclass:CompetenceClassificationScheme ; fam:extracted-from test:item1 ; oa:item test:topic-annotation-2 , test:topic-annotation-1 . test:topic-annotation-2 a fam:TopicAnnotation ; fam:confidence "0.2823413046977258"^^xsd:double ; fam:extracted-from test:item1 ; fam:topic-label "Kompetent"@de , "Competent"@en ; fam:topic-reference compclass:Competent . test:topic-annotation-1 a fam:TopicAnnotation; fam:confidence "0.7176586953022742"^^xsd:double ; fam:extracted-from test:item1 ; fam:topic-label "Inkompetent"@de , "Incompetent"@en ; fam:topic-reference compclass:Incompetent .
NOTE that the above listing does not include triples for the mmm:Item, mmm:Part and mmm:Asset
The OpenNLP Classification Extractor returns a single Content Classification test:topic-classification-1 with two Topic Annotations describing that the text was classified with:
- 72%
compclass:Incompetent - 28%
compclass:Competent