The MICO platform is an ambitious research and development project to realize the value of cross-media analysis and querying in a number of use cases.
One of the main components of the MICO platform is the recommendation system used to find and provide data the user may be interested in.
Recommender systems have changed the way people find information. Based on patterns of behaviour to make recommendations from content that the user is most unlikely unaware of. The technology behind recommender systems has evolved over the past 20 years into a rich collection of tools that enable the practitioner or researcher to develop effective recommenders.
These systems use different kinds of information in order to try to build specific models useful for the finding task. With the MICO platform, the systems can leverage all the information analyzed and extracted by the platform to enrich and extend these models, creating richer models which can provide more accurate recommendations to the user.
And not only that, the idea behind MICO recommender system is the cross-media recommendations which can be explained as recommendations that have been generated using information from other sources which may not be in the same media type.
For example, if a user has viewed a collection of images containing lions and the user has liked those images, MICO recommender can, by means of all the textual and semantic information extracted by the MICO platform, to provide documents, posts, videos, fragment of videos where lions appear and even restrict the recommendations to only the same places of the viewed images.
In MICO, we address three main types of recommendations: content-based recommendations, collaborative filtering (recommendations based on the user-item interactions) and recommendation of users. How to compare items and users and what kind of information has to be used to calculate the similarity is the most important part and thanks to the MICO platform we can have many features (extracted by MICO platform) which can be leveraged for this process.
We have been evaluating some tools around recommendation systems that help us to build the MICO recommender. We have evaluated in depth two widely used tools: Apache Mahout and PredictionIO
Apache Mahout

Apache Mahout is a project of the Apache Software Foundation to produce free implementations of distributed or otherwise scalable machine learning algorithms focused primarily in the areas of collaborative filtering, clustering and classification. Many of the implementations use the Apache Hadoop platform.
Basically Mahout provides a framework which can be used to build a recommendation systems. As stated before, it provides collaborative filtering and clustering algorithms, so it can support two out of the three kind of recommendations we need.
For MICO scenario, two main advantages can be highlighted from the use of Mahout:
- It’s a library so it can be extended and combined as needed
- Similarity functions we might need can be implemented and integrated
So, at a first glance it can be a very good tool for our needs
PredictionIO
![]()
PredictionIO is an open source Machine Learning Server. It empowers developers and data scientists to build smart applications with data productively.
PredictionIO currently offers 2 basic engine templates for Apache Spark MLlib:
- Recommendation – with MLlib ALS
- Classification – with MLlib Naive Bayes
It is shipped with some templates providing examples about the included Algorithms.
PredictionIO is a platform, so it already provides many components that can be used and not only the underlying framework. Its architecture is based on different applications which consist on different engines (the base of recommendation algorithms) built with a set pluggable components that compose the recommendation algorithm.
Each application has a separate space to store data that can be used by the engines in the recommendation algorithm. The next picture shows these things:
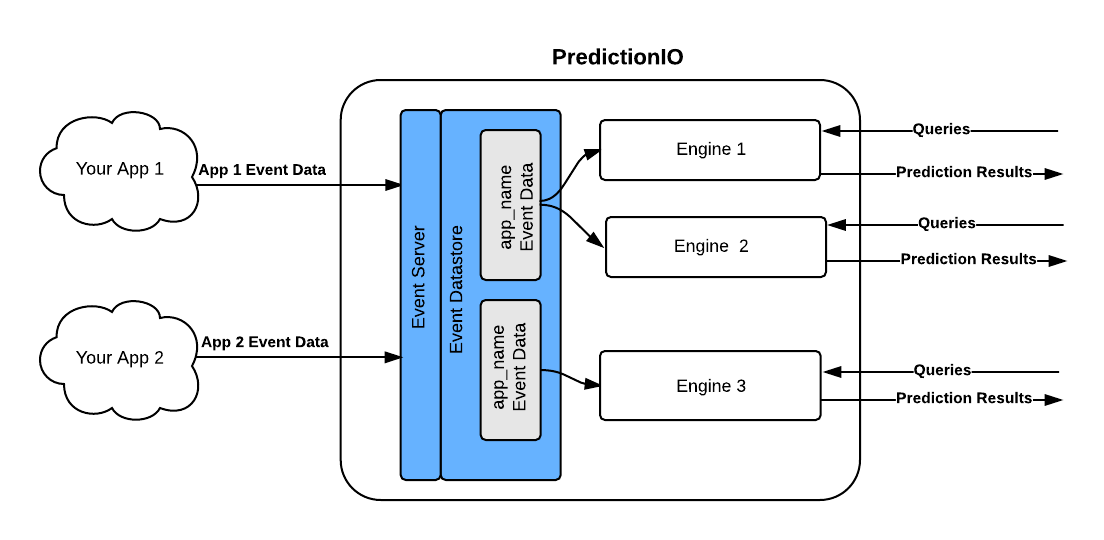
When a Engine is built and configured (data source, algorithm, model, …), it has to be trained in order to generate the recommendation model. After the training, the engine is deployed which creates an HTTP endpoint ready to receive queries and return recommendations based on the trained model.
For all the metadata PredictionIO manages, it uses a ElasticSearch instance, which can be also used for other purposes.
The next image presents the components forming an engine instance:
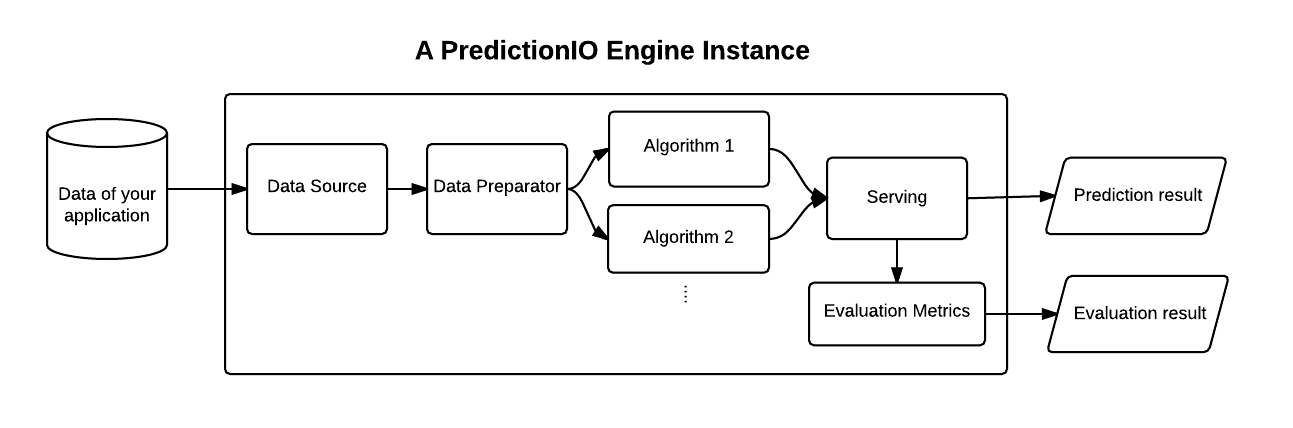
For MICO scenario, all the infrastructure PredictionIO provides and some algorithms can be leveraged, making PredictionIO a very good candidate tool to be used as well.
MICO Recommendation System
In MICO, we have to cover different requirements in order to build the recommendation system:
- User Activity and Context Monitor
- Provide services for tracking the user activity in the systems and represent them in a standard way
- User Similarity Calculator
- Find users that have common traits (profile, tastes, opinions…)
- Subject-type analysis
- Find similar items to a given one
- Cross-Media Content Recommender
- Recommender Framework
- REST API for Cross-Media recommendations
After some studies, the PredictionIO platform can ease some of the tasks needed to build the MICO recommendation system, because it already provides many of the components that will be part of the system.
Talking about the algorithms, PredictionIO does not provide all the functionality MICO recommender system needs (like some Machine Learning algorithms needed to cover some requirements) but in that case, Apache Mahout can be used and integrated inside PredictionIO engines to supply the missing functionality and algorithms MICO recommender needs.
In conclusion, a combination of both tools will be used in MICO to build the recommendation system that will be part of the MICO platform.