Orchestrating Extractors
MICO Pipelines are a combination of extractors in a graph like structure to be executed in a specific order to produce cross-media annotations. In order to have a first system ready by the start of the project we implemented a simple orchestration approach in our first MICO broker version. It used a simple mime type-based connections (i.e. string comparison) approach to register extractor processes, determine their dependencies, and to automatically configure pipelines based on these dependencies. However, this meant that all possible connections between all registered extractor processes were established, including unintended connections or even connections producing loops. Therefore, the approach had to be improved in order to support the following features:
- Standardized way of parameter specification passed to the extractor during start-up
- Means of pipeline configuration defining the extractors involved and their parameters
- End-User controlled start-up and shut-down of extractors establishing a pipeline for a specific purposes
We opted for an approach using a mixture of bash scripts and servlet configurations which is shown in the figure below. Every extractor deployed for the MICO system is obliged to support standard start-up and shut-down command line parameters. It also needs to be packaged with a short description bash script specifying the name, description and system (native, Java) it is running for. For easy changes and updates, the pipelines are configured in a separate Debian package. They specify the extractors to be loaded and the parameters to be passed in addition to the run/stop arguments.
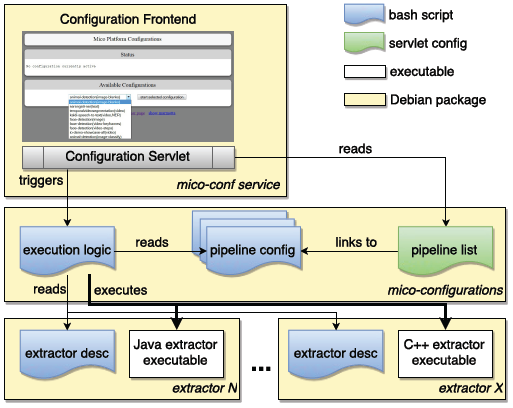
MICO extractor pipeline orchestration
However, this approach is still very limited, and one of the main priorities of year three of the project is to extend the extractor model and the implementation of the new broker. This will be described in future posts – stay tuned!
Pipelines
The extractors are pretty useless without extractor pipelines. Based on the selected MICO Showcases we created them at different levels of complexity.
For instance, the initial version of the Zooniverse pipeline to support image classification in Snapshot Seregenti, only required an animal detection task (it will soon be extended to also include textual analysis extractors):

MICO Zooniverse showcase pipeline for animal detection
In contrast, we designed a more complex pipeline for the InsideOut News Video showcase, which includes extraction from all kinds of media. We also provide parts of this pipeline (yellow and orange colored rectangles) as separate pipelines. The pipelines receives a video, segmenting them into shots, also extracting key frames and shot boundary images on which face detection is applied. In parallel, it separates the audio track from the video, uses ASR to derive text, and performs named entity recognition on the text. One can use the multitude of annotations of this pipeline, e.g. to do a query like: “Show me all video shot (video segmentation), where a person (face detection) in the video says (speech to text) about a specific topic (NER).”
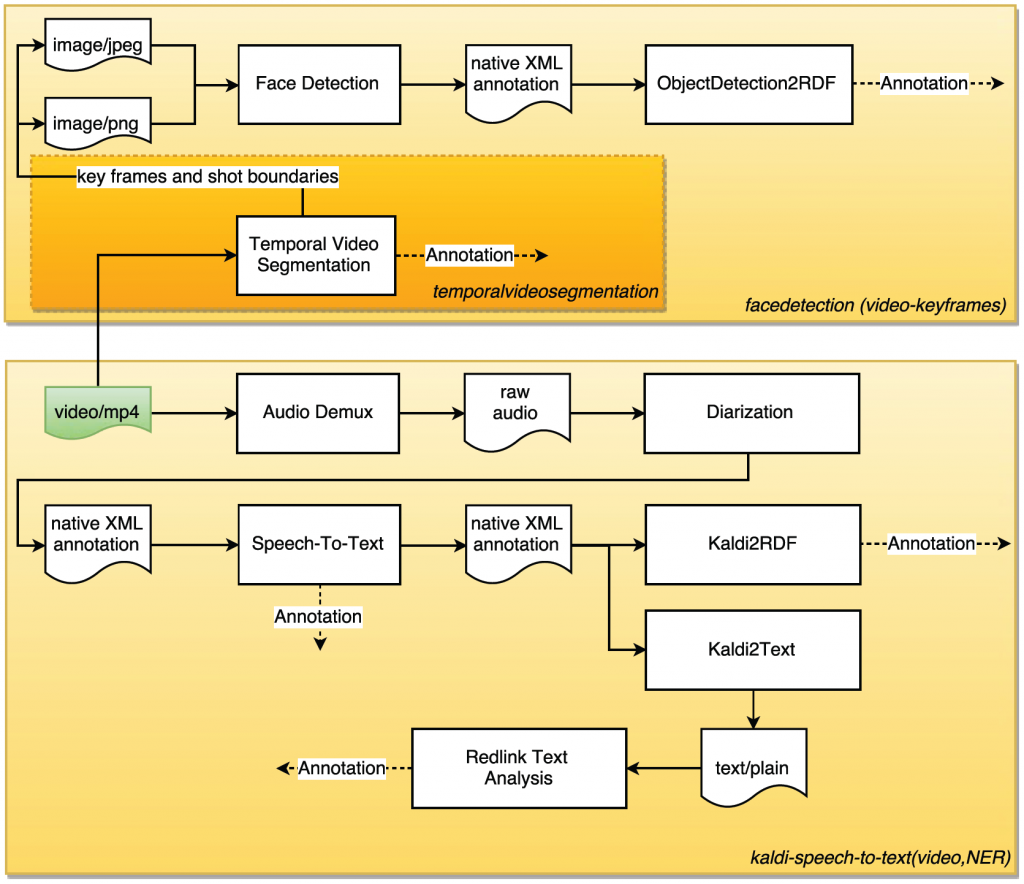
MICO InsideOut10 showcase pipelines and sub-pipelines
