Design principles
Based on the requirements summarized in the last blog post, the MICO broker design and implementations followed several high-level principles and assumptions:
(1) Registration information is provided at different times, by different users / user roles: Some elements of the extractor information that is necessary for workflow planning and execution can be provided during packaging by the developer (extractor I/O and properties), while other parts can only be provided after packaging, by other developers or showcase administrators (semantic mapping, and feedback about pipeline performance).
As one consequence, extractor input and output was not defined only via MIME-type, but via three data types:
- MIME-type, e.g. image/png
- syntactic type, e.g. image region
- semantic tags, e.g. face region
MIME-types and syntactical types are pre-existing information that a extractor developer or packager can refer to using the MICO data model or external sources: In contrast, semantic tags are subjective, depending on the usage scenario, will be revised frequently, and are often provided by other developers or showcase administrators. In many cases, they cannot be provided at extractor packaging time, nor should they be provided then – such information does not imply any component or component interface adaptation.
Moreover, a dedicated service for extractor registration and discovery was introduced to address many of the mentioned requirements, providing functionalities to store and retrieve extractor information, supporting both a REST API for providing extractor registration information, and a front-end for respective user interaction, which is more suitable to complement information that is not or cannot be known to an extractor developer at packaging time. Workflow planning and execution can reuse this information for their respective purposes.
(2) For the broker data model, the existing MICO metadata model (MMM) should be reused as far as possible. This would go especially for syntactic types, and wherever applicable, extractors and extractor versions, types etc. should be uniquely identified via URIs.
(3) For workflow execution, Apache Camel was found to be a suitable technology for MICO, mostly due to the fact that it supports many communication protocols and EIP, which provides a great level of future flexibility for the platform. At the same time, however, it was clear that Camel had t be complemented by MICO-specific components for retrieving data from Marmotta to put them into Camel messages, in order to support dynamic routing.
(4) The broker should not deal with managing scalability directly. Instead, it should support scalability improvements beyond the project lifetime by keeping information about extractor resource requirements in the broker model, thus allowing remote extractor process startup and shutdown for future implementations.
(5) Semi-automatic approaches and a respective GUI could substantially simplify the process of workflow creation: Manual workflow creation had turned out to be a very difficult process, due to the need to consider many constraints and interdependencies, depending on the extractor I/O types, but also due to the different content, goals, and contextual information of a specific application. Considering this, we found that it would be desirable to simplify the task of workflow creation by using a semi-automatic approach that considers the various constraints related to extractors and extractor dependencies, and a respective GUI for user interaction.
(6) The system should support management of content set and job management and related feedback from showcase users / admins: While not being part of the core platform and requiring functionalities beyond the core platform e.g. related to user management, we found that it would be useful to support the definition of ContentSets, mapping of workflows to ContentSets, resulting in Jobs, and providing and retrieving feedback on how well certain extractors and workflows perform on certain datasets and use cases. All related functionalities would however become part of the workflow management tools, which do not belong to the core platform.
Data model
The broker data model needs to support extractor registration, workflow creation and execution. It uses URIs as elementary data and extends the MICO MetadataModel (MMM) (http://mico-project.bitbucket.io/vocabs/mmm/2.0/documentation/}. The model is composed of four interconnected domains, represented by different colors:
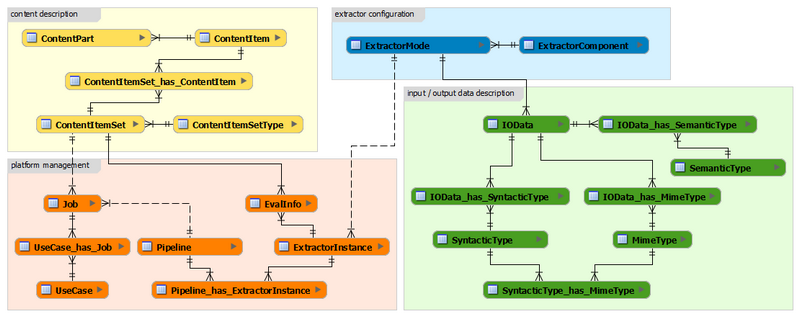
The content description domain (yellow) includes 3 main entities:
- ContentItem captures information of items that have been stored within the system.
- As described in MICO-Dx.2.2, MICO items combine media resources and their respective analysis results in ContentParts.
- ContentItemSet is used to group several ContentItems into one set – such a set can be used to run different workflows on the same set, to repeat analysis with an updated extractor pipeline configuration, etc.
The extractor configuration domain (blue) with two main entities:
- ExtractorComponent, which captures general information about registered extractors, e.g., name and version and
- ExtractorMode, which contains information about a concrete functionality (there must be at least one functionality per extractor), which includes information provided by the developer at registration time, e.g., a human-readable description and configuration schema URI. For extractors which create annotations in a format different from RDF, it includes a output schema URI.
The input/output data description domain (green) stores the core information necessary to validate, create and execute extractor pipelines and workflows:
- IOData represents the core entity for the respective input or output to a given ExtractorMode.
- MimeType is the first of three pillars for workflow planning / creation as outlined above. RDF data produced by extractors will be labeled as type rdf/mico.
- IOData_has_MimeType connects I/O data to MimeType. It has an optional attribute
- FormatConversionSchemaURI which signals that an extractor is a helper / aux component with the purpose of converting binary data from one format to another (e.g. PNG images to JPEG images).
- SyntacticType is the second pillar for workflow planning / creation. For MICO extractors which produce RDF annotations, the URI stored should correspond to an RDF type, preferably to one of the types defined by the MICO Metadata model. For binary data, this URI corresponds to a Dublin Core format.
- SemanticType is the third pillar for workflow planning / creation and captures high-level information about the semantic meaning associated with the I/O data. It can be used by showcase administrators to quickly discover new or existing extractors that may be useful to them, even if the syntactical type is not (yet) compatible – such information can then be exploited to request an adaptation or conversion.
- The optional field cmdLineSwitch can be used to control in which format a binary output, e.g. an image, is provided. For extractors requiring multiple inputs or providing multiple outputs, the relative index is stored as an attribute.
The platform management domain (orange) combines several instances related to platform management:
- ExtractorInstance is the elementary entity storing the URI of a specific instance of an extractor mode, i.e., a configured extraction functionality available to the platform. The information stored in the URI includes the parameter and I/O data selection and further information stored during the registration by the extractor itself.
- EvalInfo holds information about the analysis performance of an ExtractorInstance on a specific ContentItemSet. This can be added by a showcase administrator to signal data sets for which an extractor is working better or worse than expected.
- Pipeline captures the URI of the corresponding workflow configuration, i.e., the composition of ExtractorInstances and respective parameter configuration.
- UseCase is a high-level description of the goal that a user, e.g. showcase administrator, wants to achieve.
- Job is a unique and easy-to-use entity that links a specific workflow to a specific ContentItemSet. This can e.g. be used to verify the analysis progress / status.
- UseCase_has_Job is a relation that connects a UseCase to a specific Job, which can be used to provide feedback, e.g., to rate how well a specific Pipeline / workflow has performed on a specific ContentItemSet
Component overview
The current broker architecture includes and interacts with the following components:
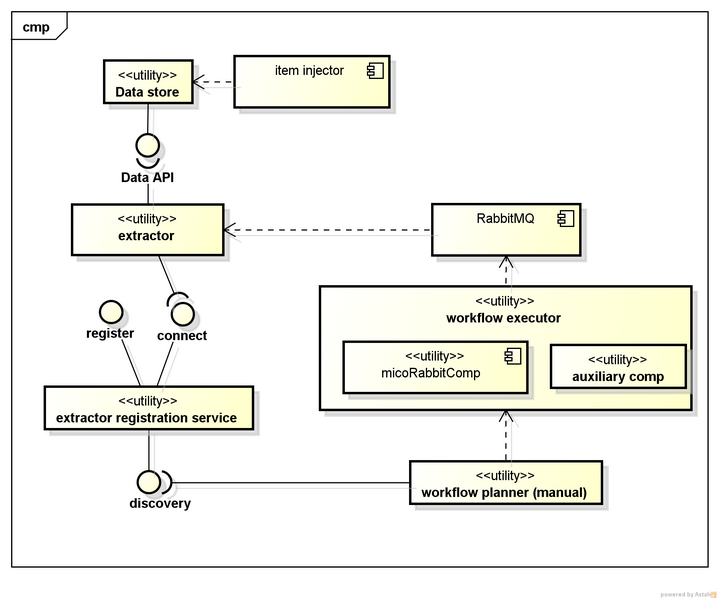
- As mentioned above, the registration service provides a REST API to register extractors* (which produce or convert annotations and store them as RDF), thereby collecting all relevant information about extractors. It also provides global system configuration parameters (e.g., the storage URI) to extractors, and provides retrieval and discovery functionalities for extractor information which is used by the workflow planner.
- The workflow planner provides semi-automatic creation and storage of workflows, i.e. complex processing chains of registered extractors that aims at a specific user need or use case. Once workflows have been defined, they can be stored as Camel routes.
- The item injector is responsible of injecting content sets and items into the system, thereby storing the input data, and triggering the execution of the respective workflow. Alternatively, the execution can also be triggered directly by a user.
- Workflow execution is then handled by the workflow executor which uses Camel, and a MICO-specific Camel auxiliary component to retrieve and provide data from the data store to be used for dynamic routing within workflows.
- Finally, all aforementioned Linked Data and binary data is stored using the data store.
Extractor lifecycle
From an extractor perspective, the high-level process can be summarized as follows (see broker_activity.png):
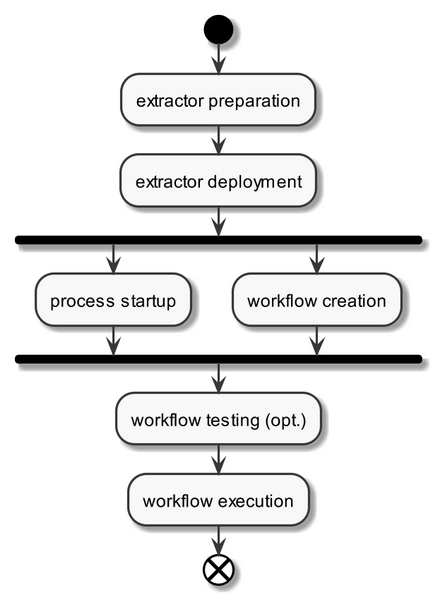
- Extractor preparation includes the preparation and packaging of the extractor implementation, including registration information that is used to automatically register the extractor component during extractor deployment and possible test data and information for the extractor.
- As soon as extractor registration information is available, it can be used for workflow creation, which may include extractor and workflow testing if the required test information was provided earlier
- For planning and/or execution, the broker will then perform an extractor process startup, and workflow execution will then be performed upon content injections or user request.
Note: Testing and automatic process startup functionalities have been designed and prepared, but are not yet implemented in broker v3.
The the next episode, we will discuss how some of the aforementioned approaches were used to support semi-automatic workflow creation for the platform.
See also:
- MICO broker (overview)
- MICO broker (part 1): relevance, history and main requirements
- MICO broker (part 3): semi-automatic workflow creation
- MICO broker (part 4): workflow execution and workflow management tools