Supporting complex and context-aware extraction workflows: A key goal for MICO
Two example queries to illustrate the MICO goals are:
- find video shots with elephants and
- find video shots where a US politician talks about Europe
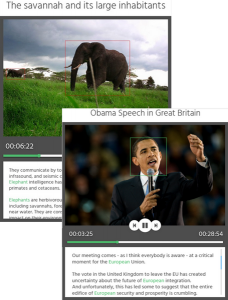
But although they are simple from the user perspective, they already require fairly complex analysis workflows. The former implies the existence of e.g. visual animal detection (for elephants being visible), audio animal detection (for elephants being audible), and possibly ASR and NER (to extract the speech transcript and determine whether elephants are being talked about). The latter implies the existence of e.g. face detection and recognition (for visual person identification) and speaker discrimination and recognition (for audio person identification), again possibly combined with ASR and NER (to extract the speech transcript and determine whether a term related to Europe is mentioned). In addition, linked data support is required to link detected entities (e.g. Obama) with terms used within the query (e.g. US politician, Europe). This shows that even to support fairly simple queries, rather complex analysis workflows are needed.
To illustrate the respective workflow in more detail, take the example of a similar yet even simpler query: find video shots in which a person talks about topic X – the workflow looks as follows:
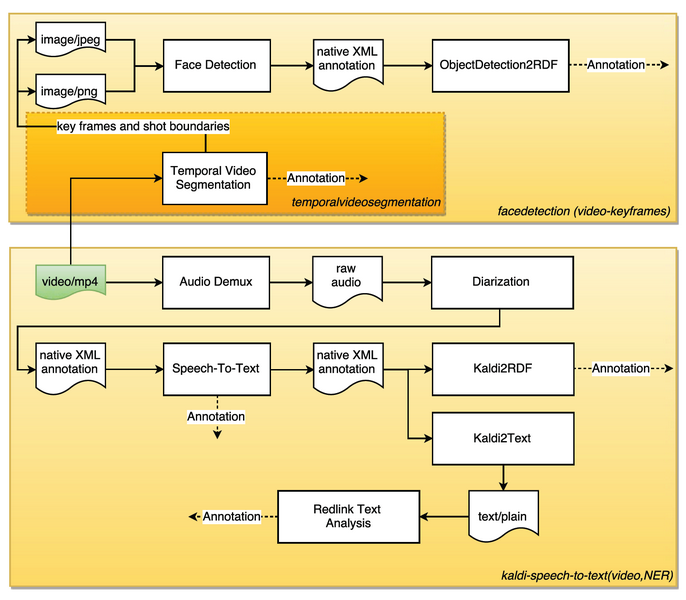
It uses mp4 videos as input, and consists of
- shot detection and key frame extraction, and subsequent face detection
- audio demux, diarization, speech2text (Kaldi) and named entity recognition (redlink service)
- several auxiliary components for data transformation
There are endless possibilities to further extend this workflow to exploit synergies among extractors, and to further improve annotation quality and search capabilities, e.g. by extracting key words from container or the respective website, including and combining speaker and face recognition, consideration of user feedback, etc. Moreover, it makes sense to consider the specific and general context in which media appears: For instance, a certain news video analysis and search application (which is the background of the example here) will pose very different requirements with respect to analysis and search than e.g. music video, TV show analysis, etc., even if the content type used s the same.
Moreover, there is a great potential in combining and intertwining extractors (e.g. audio and video person identification as described in the Obama example at the beginning), and to consider contextual information. This goes for many more cases in various application domains.
We believe that there is a general trend to shift from using individual standalone extractors to multi-modal and context-aware extractor workflows. Providing all necessary technologies has been the key goal of the MICO project form the start, and supporting the creation and execution of respective workflows – the broker – is a crucial element for this.
A brief MICO broker history
The inital broker v1 was implemented on top of RabbitMQ: Extractor orchestration was implemented using different message queues for extractor service registration, receiving new content, and extractor result provisioning. The implementation completely decoupled extractors from extractor orchestration, in order to support free choice of extractor programming languages and potential distribution of extraction tasks. For convenience purposes, an Event API exposed a basic set of instructions for extractors to interact with the broker, available in both Java and C++ (other languages supporting AMQP could be used as well).
The described v1 proved to be quite stable, especially thanks to using the RabbitMQ messaging infrastructure, but orchestration was based on very simple, MIME-type-based comparison: Upon registration of a new extractor process, all connections that were possible for that MIME-type were established, which lead to unintended ones and loops, among other problems. Hence, it was clear that further improvements were necessary.
To address some of the most pressing issues, while keeping backward-compatibility with the Event API, several improvements were provided shortly after broker v1, with the so-called pipeline configuration tools, consisting of a mixture of bash scripts and servlet-based Web UI. This provided additional support for extractor parameter specification, user-controlled workflow configuration and user-controlled service startup/shutdown.
However, it soon became obvious that the broker required a re-design and significant further improvements. Hence, an extensive list of requirements (a broker wishlist) was compiled, which is described in the following.
The broker wishlist
The broker wishlist included many requirements, which are summarized in the following.
Requirements regarding extractor properties and dependencies:
- support for provisioning of different extractor I/O types at different times, by different users / user roles: it became clear that we would need information about MIME type, but also further information about syntactics and semantics for extractor input and output to support workflow creation and execution, and that such information would be provided by different users and user roles, at different times
- support for extractor configuration and different extractor modes, i.e., different functionalities with different input, output or parameter sets, encapsulated within the same extractor component
- support for multiple extractor inputs and outputs
- support for extractor versioning
Requirements regarding workflow creation and execution:
- simplified workflow creation – which, up until then, was very complicated
- extractor dependency checking during planning and before execution, to avoid problems related to missing connections, loops, unintended connections etc. as early as possible
- support for error handling and workflow progress tracking
- support for routing, aggregation, splitting within extraction workflows, and more general, Enterprise Integration Pattern (EIP) support
- support for dynamic routing, e.g, for context-aware processing, using results from language detection to determine different subroutes (with different extractors and extractor configurations) for textual analysis or speech2-to-text optimized for the detected language
- support for multiple workflows per MICO instance
- support for automatic process management, i.e. possibility to startup and shutdown process, for scalability purposes – which is the only feature that has not been implemented yet
Besides, the goal was also to ensure backward-compatibility with the existing infrastructure (especially regarding RabbitMQ and the Event API) as far as possible, to reduce efforts for extractor adaptation, and to apply existing and established standards and technologies for broker implementation, wherever possible.
With the exception of the last point (automatic process management), which was prepared but had to be dropped as a requirement for the project lifetime (it is one of the first issues to be addressed as a follow-up), all other requirements have been implemented in year three of the MICO project and have been provided with broker versions v2, v2.1, v2.2 and finally, v3.
Design and implementation of both the broker (v3), workflow creation, and workflow execution and workflow management tools will be described in future posts.
See also:
- MICO broker (overview)
- MICO broker (part 2): principles and overall design
- MICO broker (part 3): semi-automatic workflow creation
- MICO broker (part 4): workflow execution and workflow management tools