Riding the Apache Camel
Once workflows have been created and stored (see blog post #3), they are available as Camel routes within the platform, which for instance look as follows:

Now, they they can be used to execute analysis workflows, using four main components for this purpose:
- The workflow executor as master component, which uses the other components and is based on Apache Camel
- The auxiliary component, a MICO-specific extension to Camel that allows data retrieval during workflow processing
- The RabbitMQ message broker serves as communication layer to loosely couple extractors and the MICO platform
- The MICO-specific Camel endpoint component that connects Camel with the MICO platform, and triggers extractors via RabbitMQ
Dynamic routing
Apache Camel supports a variety of protocols and features, and supports many Enterprise Integration Patterns (EIP), all of which is why we chose it for the project. However, we had one additional key requirements that made it necessary to implement extensions to Apache for MICO purposes: dynamic routing. Dynamic routing allows us to fetch information from the knowledge base, including data that was annotated by previous extraction steps within a workflow, and to use that information to dynamically choose different subroutes within a workflow.
The following illustrates how this approach works, using the example of a speech2txt workflow for mp4 videos:
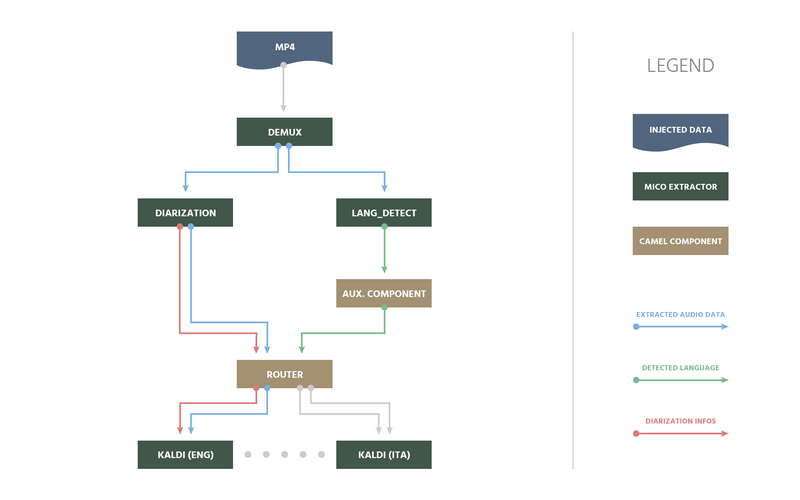
After demuxing, the audio stream of the mp4 is stored and provided to diarization, where audio content is segmented based on speakers and sentences, and language detection is applied. Both analyze the audio material in parallel, and store their annotations in Marmotta.
At this point, dynamic routing is applied to optimize performance: The auxiliary component fetches annotation data about the detected language from Marmotta, and puts it into the Camel message header. It knows where to locate that information, because the abstract location has been provided during the registration process of the respective extractor using LDpath. Afterwards, the language information within the Camel message header is evaluated by a Camel router component, which triggers the ASR extractor optimized for the detected language.
Beyond this example, there are many use cases where dynamic routing capabilities can be applied. Most importantly, it can be used to implement context-awareness within the analysis workflow, by being able to reuse any metadata from preparation process, crawling, or previous analysis steps.
Workflow management tools
Many of the features and approaches discussed in this blog series were not originally planned for the project, but were implemented simply because we found that they were very useful. One further example to this, which became evident within the final phase of the project, was to also start working on some initial workflow management functionalities, especially by supporting the usage of ContentSets and Jobs: ContentSets group pre-defined sets of content which have common characteristics, convey contextual information and can (should) be processed and analyzed using the same workflows. Jobs, on the other hand, represent assignments of ContentSets to Workflows, and provide a simple means to monitor processing and analysis progress.
A first prototype implementation of workflow management tools was provided within the final month of the project, not as part of the MICO broker, but as an extra functionality. It was implemented as a set of RESTful-based webservices, to be used with appropriate XML and/or JSON files by showcase administrators.
A first set of services is addressing the management of XML camel routes similar to the one reported above, created by using the workflow creation tool presented in our previous blog. The management tool also allows for inspecting the status of workflows, as in the figure below:
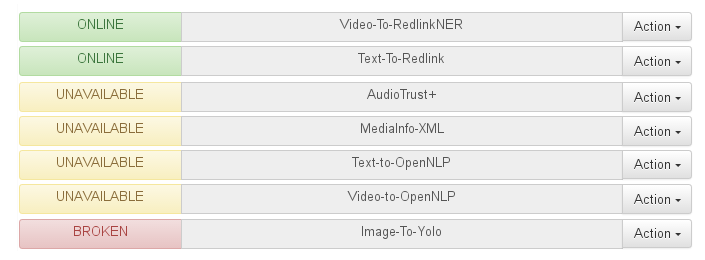
Workflows that are “Online“ can immediately be used for injection and are thus displayed in green, while workflows that are “Unavailable“ can be expected to return online as soon as the respective extractors are connected to the platform again — hence the yellow color. Workflows that are “Broken“ cannot be expected to run anymore, and should be deleted. A fourth status type that is not visible in the example above, finally, is “Runnable“ in green, which signals that workflows could be started automatically by the Broker.
A second set of services is addressing the management of items and of online and offline content sets, where
- Items are single resources that could be analyzed, whether being available locally or remotely
- Offline content sets consist of a list of files available on the machine, sharing the same syntactic Type, each of which should be analyzed independently by the same workflow(s)
- Online content sets consists of a list of file groups (i.e., of item bundles) available online, that can be downloaded automatically. Each group (i.e., each sub-set of items) should be analyzed at once using the same workflow(s). An example of such groups are images with attached user comments
The various items and content sets, if public, can be shared across different users, by tracking ownership and visibility of the uploaded content.
A third type of service is addressing the management of jobs, i.e. of requests for processing specific content sets with specific extractor workflows. This can be used for several purposes:
- Status tracking of the whole set, i.e., the status of the processing (in progress, successfully completed, pending, error) is available on a per-element basis
- Performance comparison between different workflows, e.g., to evaluate which kind of animal detectors perform the best on the same content
- Performance comparison between workflow parameter setups, e.g., to evaluate which parameters have which impact on which content items
In the future, the available services are going to be extended, in combination with automatic process startup and testing functionalities (see blog post #2) in order to further simplify the (non-trivial) task of managing workflows, content, and annotation results.
See also:
- MICO broker (overview)
- MICO broker (part 1): relevance, history and main requirements
- MICO broker (part 2): principles and overall design
- MICO broker (part 3): semi-automatic workflow creation