 As previously announced, the MICO project was presented at IBC 20106 (Sep 9-13) with a demo at the Fraunhofer IDMT booth. The following provides a summary of
As previously announced, the MICO project was presented at IBC 20106 (Sep 9-13) with a demo at the Fraunhofer IDMT booth. The following provides a summary of
- the demo setup
- overall impressions
- received feedback regarding the overall platform, extractors and showcases.
Demo setup
 Our demo setup included:
Our demo setup included:
- Intro slides, presenting the relevance and challenges of multi-modal, context-aware analysis and semantic search
- Slides and screen-casts for the individual MICO showcases, provided by
- University of Oxford, on Zooniverse and the Snapshot Serengeti project
- InSideOut10, with an introduction to Helixware and Shoof
- Umeå University, presenting the SmartVideo application
- Fraunhofer IDMT, demonstrating the AudioTrust+ R&D project
- A running instance of the MICO platform equipped with
- The MICO workflow creation web application
- A live demo of a MICO workflow execution
- A few pre-defined MICO workflows
- A live demo of the AudioTrust+ audio tampering detection workflow and SPARQL query of the MICO metadata model, and of the respective existing AudioTrust+ tampering detection front-end
- Several live demos of AudioTrust+ use cases that are going to be included into MICO in the near future, including audio segment matching and audio phylogeny: All these approaches have many synergies and hence can benefit greatly from a multi-modal analysis platforms such as MICO
Overall impressions from the exhibition
Considering that the demo was about an integrated prototype from a EU project (while most visitors tend to be focused on ready-to-use-products), we were very happy about 30+ companies visiting us at the booth. We also had the impression that the demo setup using several sets of introductory slides and demos worked well in order to quickly adapt to visitor interests. On the other hand, screen-casts were rarely used and did not prove that useful.
Regarding individual topics, visitors tended to be most interested in
- the overall MICO idea and architecture
- individual extractors
- MICO showcases, especially in AudioTrust+ (Fraunhofer IDMT) and in cloud aspects (InsideOut10)
Feedback regarding the overall MICO challenges and platform
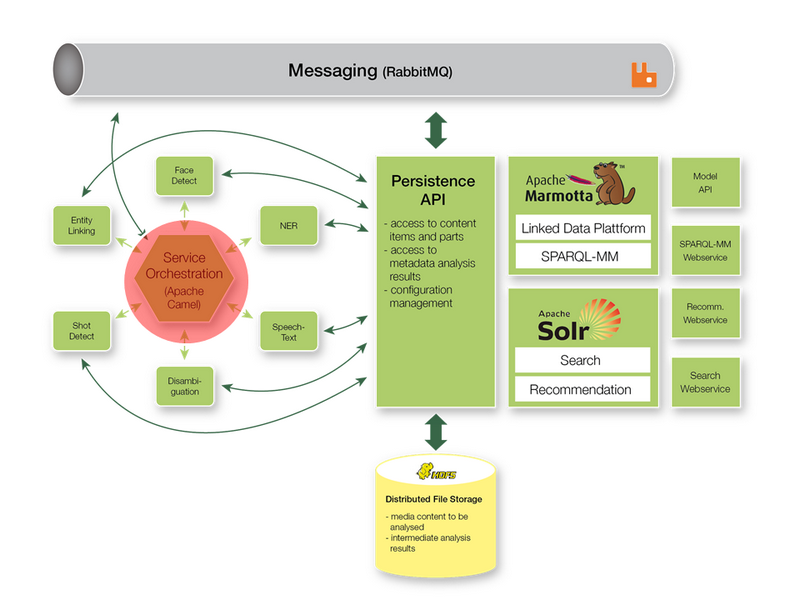 Judging from discussions at the booth, broadcasters do not yet have solutions in place for multi-/cross-modal and context-aware multimedia analysis, semantic search and recommendation. Many of them, however, are fully aware that this will be a key question, especially for archives, and that they need to make strategic decisions about this in the very near future. Therefore, they were interested in how MICO dealt with the respective technical challenges, and what our position regarding follow-up projects was.
Judging from discussions at the booth, broadcasters do not yet have solutions in place for multi-/cross-modal and context-aware multimedia analysis, semantic search and recommendation. Many of them, however, are fully aware that this will be a key question, especially for archives, and that they need to make strategic decisions about this in the very near future. Therefore, they were interested in how MICO dealt with the respective technical challenges, and what our position regarding follow-up projects was.
The fact that the MICO platform is an integrated prototype which needs to be significantly extended did not surprise visitors: They did not expect a ready-to-buy product, but were all the more interested in how they could be addressed after the project lifetime. Topics for improvements that came up during discussions included e.g.
- integration of additional “key extractors” for various application domains
- platform stability, scalability, and security aspects
- further integration of user feedback and user interaction
- training of extractors by users
- PaaS aspects (including specific security requirements)
- testing and quantitative evaluation not only of single extractors, but also of integrated workflows
All in all, it became clear that MICO has a lot to offer to many visitors, and there was positive feedback especially to the following domains:
- Simplified extractor integration and C++ support (those who had experience in this domain where fully aware of the related complexities)
- Complex, dynamic workflow support and related workflow creation; visitors made minor suggestions, and some of them have already been integrated into the app after IBC
- Media-aware querying using SPARQL-MM, almost always combined with the question on how the complexity of SPARQL could be taken away from the user with templates and dedicated API and integrating natural language query approaches
- The MICO metadata model and in general the semantic web based approach, which was welcomed by many visitors, almost always combined with ideas on how scalability issues could be addressed, and a few visitors explaining which Triple Store they have investigated or used for this purpose
- Cross-media recommendation, which was considered the most interesting “enabler” by several of the visitors
The fact that the MICO core is available under a business-friendly Apache license, and that the overall approach is aiming at combining OSS and CSS extractors, was very useful for these discussions.
Feedback regarding extractors and extraction
 Almost all visitors were aware of the potential of using automatic extraction (especially those from the archive domain). However, many had only limited practical experience with automatic extraction so far, and in almost all cases, things seem to start with Automatic Speech Recognition (ASR) and Named Entity Recognition (NER). Consequently, questions related to ASR and NER such as the following emerged frequently:
Almost all visitors were aware of the potential of using automatic extraction (especially those from the archive domain). However, many had only limited practical experience with automatic extraction so far, and in almost all cases, things seem to start with Automatic Speech Recognition (ASR) and Named Entity Recognition (NER). Consequently, questions related to ASR and NER such as the following emerged frequently:
- Which OSS and CSS solutions and services for ASR exist, and how well do they work?
- How well does Kaldi ASR perform? How can it be extended with new language models?
- How can Kaldi ASR be used for key word search? How can customized NER vocabularies be supported?
After the exhibition, we therefore decided that this should be addressed with an additional ASR / NER report.
Regarding A/V extraction, requests were mostly related to person identification, i.e. face detection / recognition, and speaker discrimination / recognition. Beyond that, there seems to be a general interest to be informed what is technically possible audio and visual analysis possibilities – several visitors claimed that is is very difficult to keep an oversight over this.
When asked about overall needs regarding extraction, not surprisingly, most visitors indicated a string interest in extractors suitable for the detection of persons, locations, events and objects. Moreover, it seems clear that there are many cases where detection should not only be based on general concepts, but should also support custom vocabularies and user training. This also goes for the detection of semantic concepts – a discussion which almost always included the notion of CNN and deep learning approaches 🙂
Feedback regarding MICO showcases and tools
Finally, there was also a lot of interest in individual showcases, regarding:
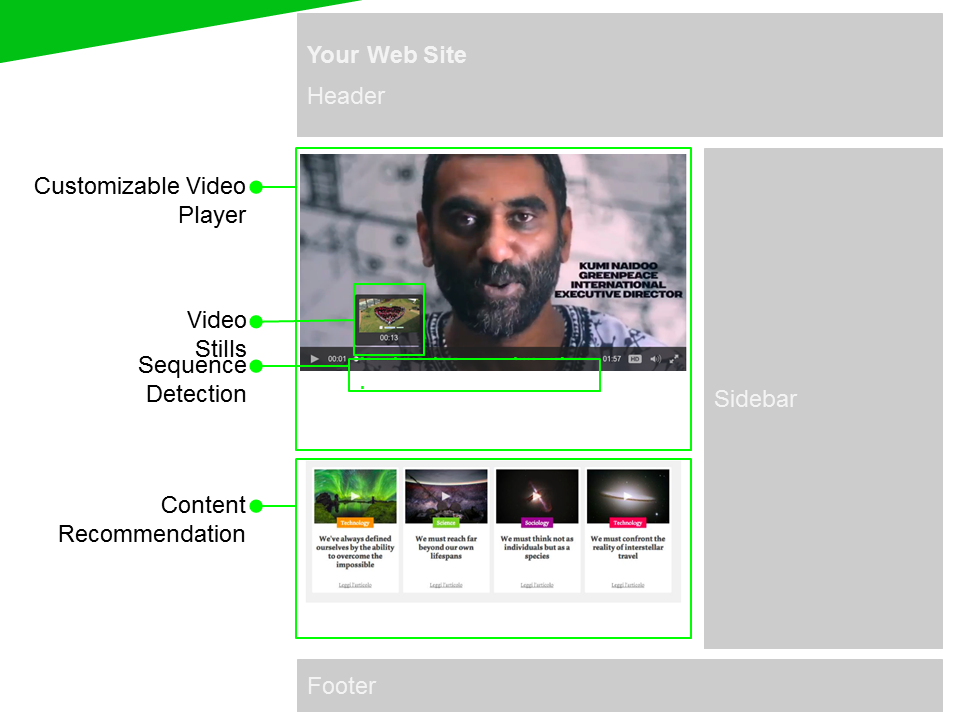 |
1. The idea of cloud-based extraction as implemented by Insideout10 using Helixware and more general, the idea of cloud-based services based on MICO ideas and the MICO platform. Several visitors indicated that such approaches could be interesting for them, but that security concerns need to be taken care of. |
| 2. The idea of how an analysis framework such as MICO can be used in combination with crowdsourcing, which can be nicely illustrated with Snapshot Serengeti from Zooniverse. From the discussions, it was clear that a tight (and customized for specific workflows) integration of automatic annotation and user interaction is important. | 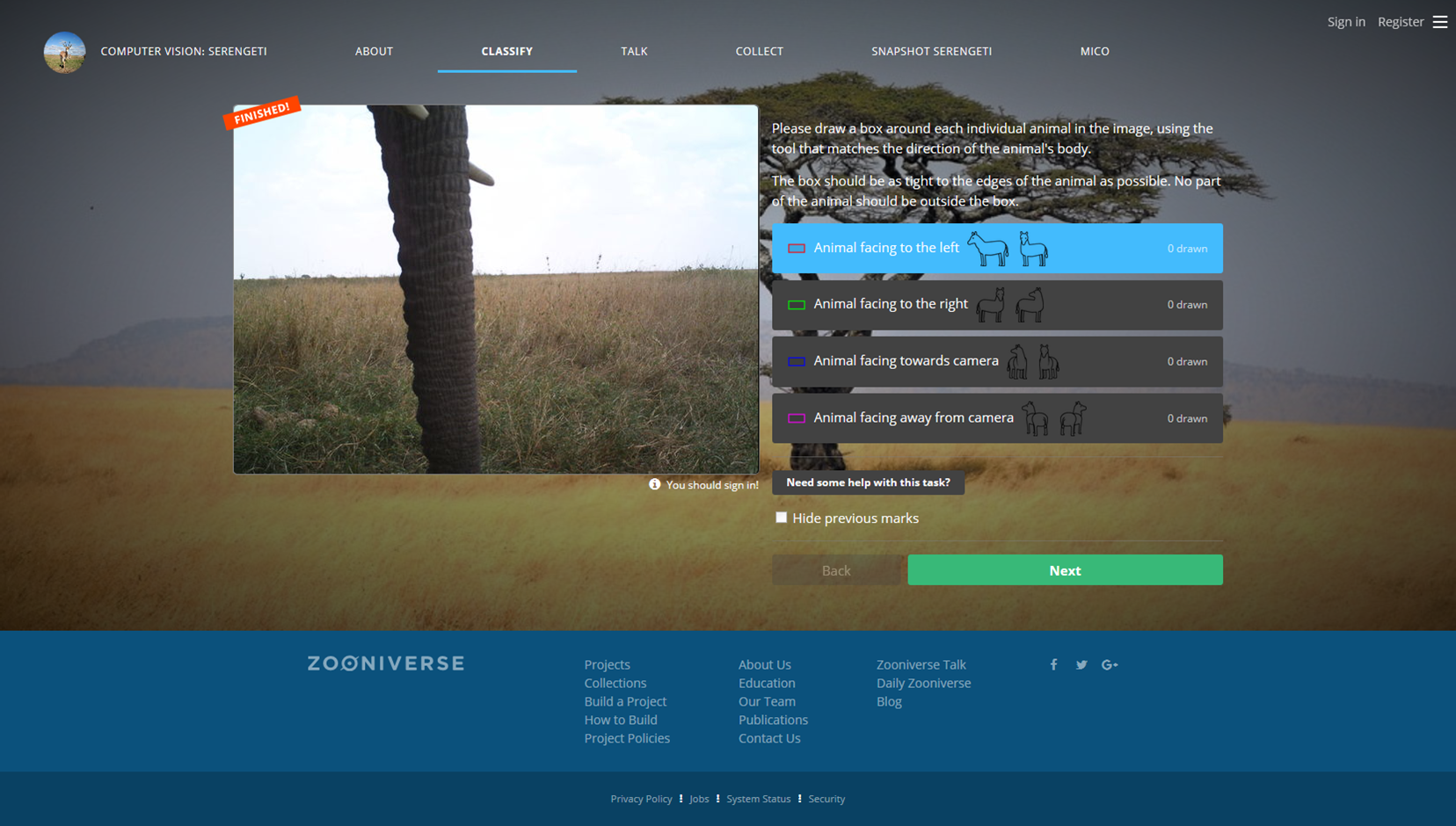 |
 |
3. Object detection within SmartVideo, on the idea of using object detection to recognize products in video, and applying key word extraction to find product names and categories. Product and logo recognition was a relevant topic for several visitors. |
The usefulness of Fraunhofer IDMT‘s AudioTrust+ showcase and related audio forensics extractors for archive, news production and monitoring purposes was discussed with many visitors, regarding:
There were discussions about several specific use cases where such tools could come in handy, and the general need to support tampering detection was confirmed. |
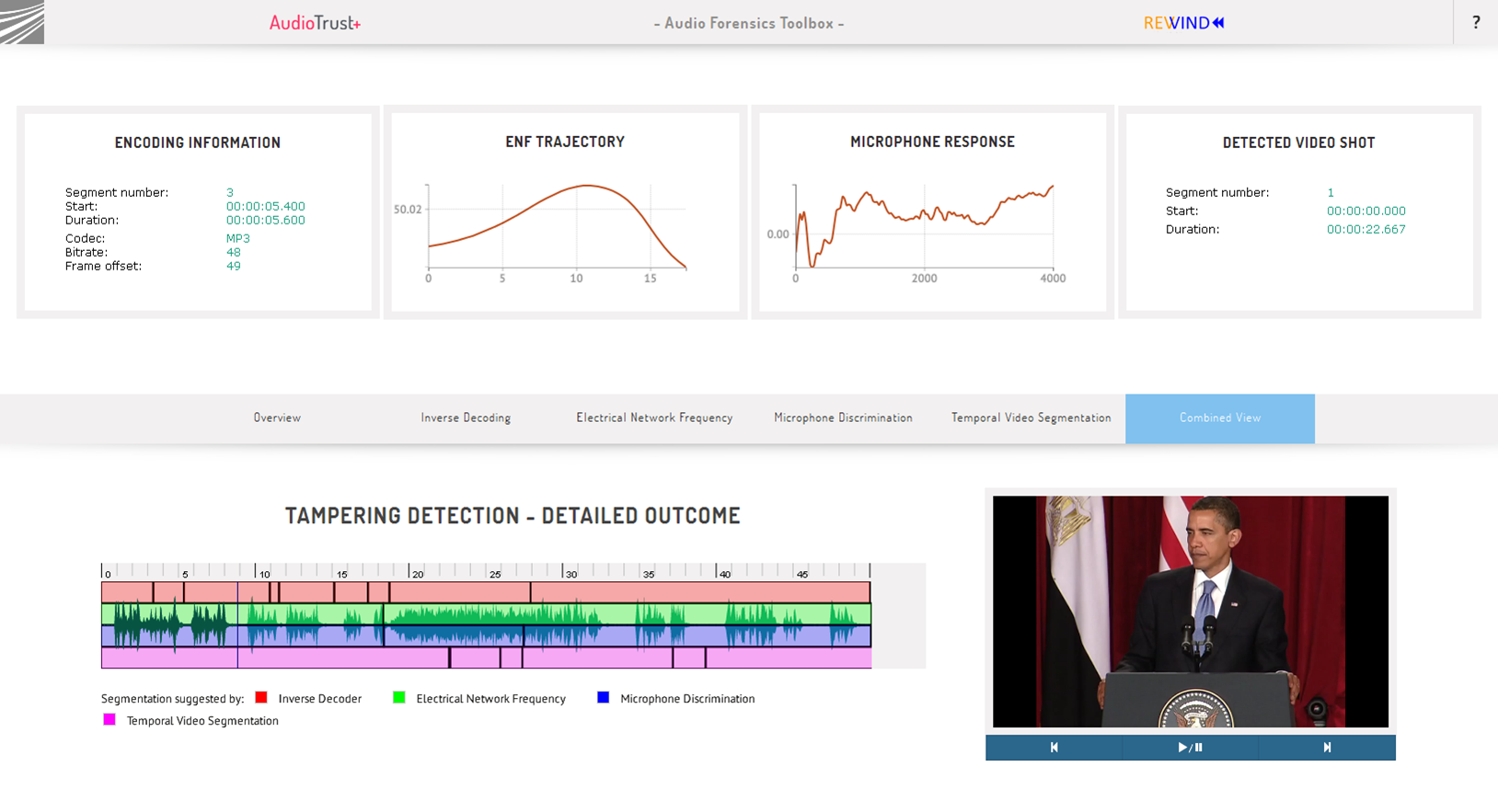 |
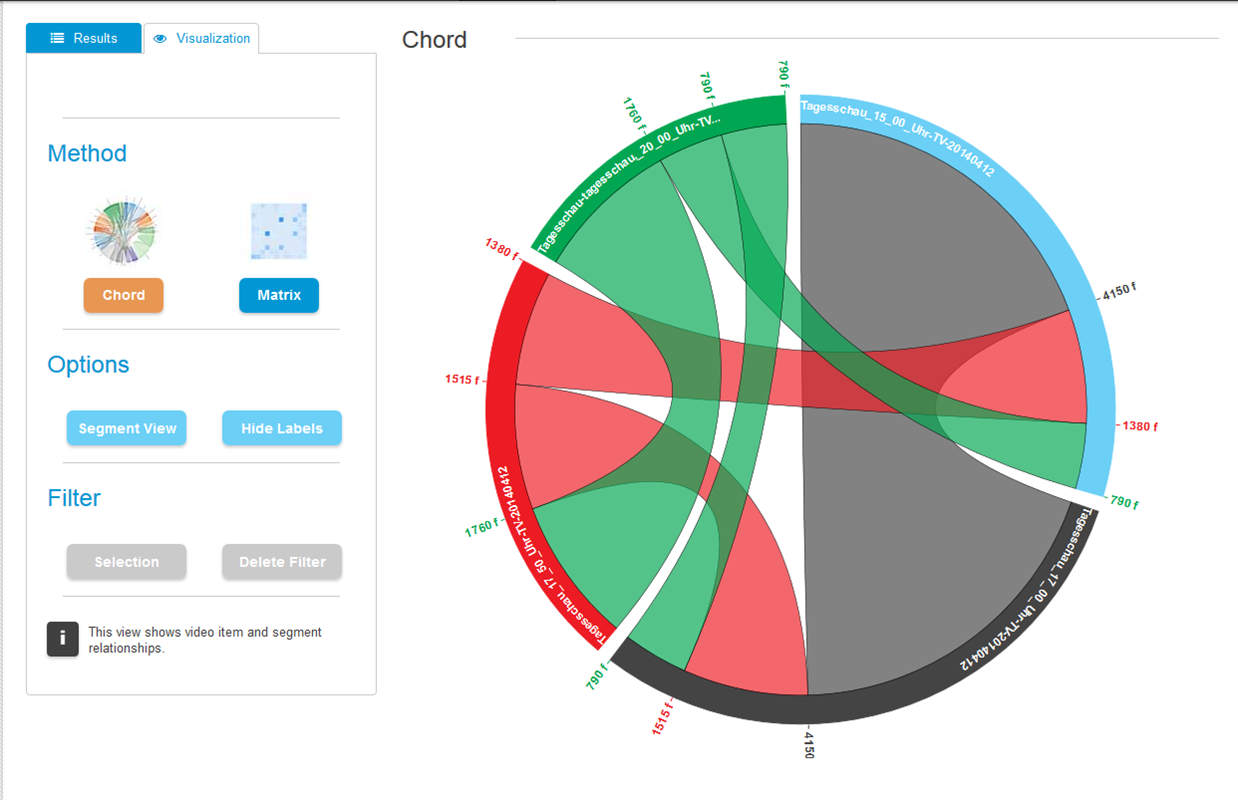 |
Audio and video segment matching from AudioTrust+, which can be used to detect redundant items and segments, track metadata throughout a system,and find items which reuse the same original material, often because they refer to the same event (this is not yet included in the MICO back-end, but planned to be integrated in the future). Such functionalities were considered useful by many visitors, especially those with an archive background. |
| Audio phylogeny from AudioTrust+, which can be used to establish the “processing history” for transcoded copies of the same item, and to differentiate between original and derived versions of the same item (this is not yet included in the MICO back-end, but planned to be integrated in the future). This was discussed mostly together with the above, segment matching. | 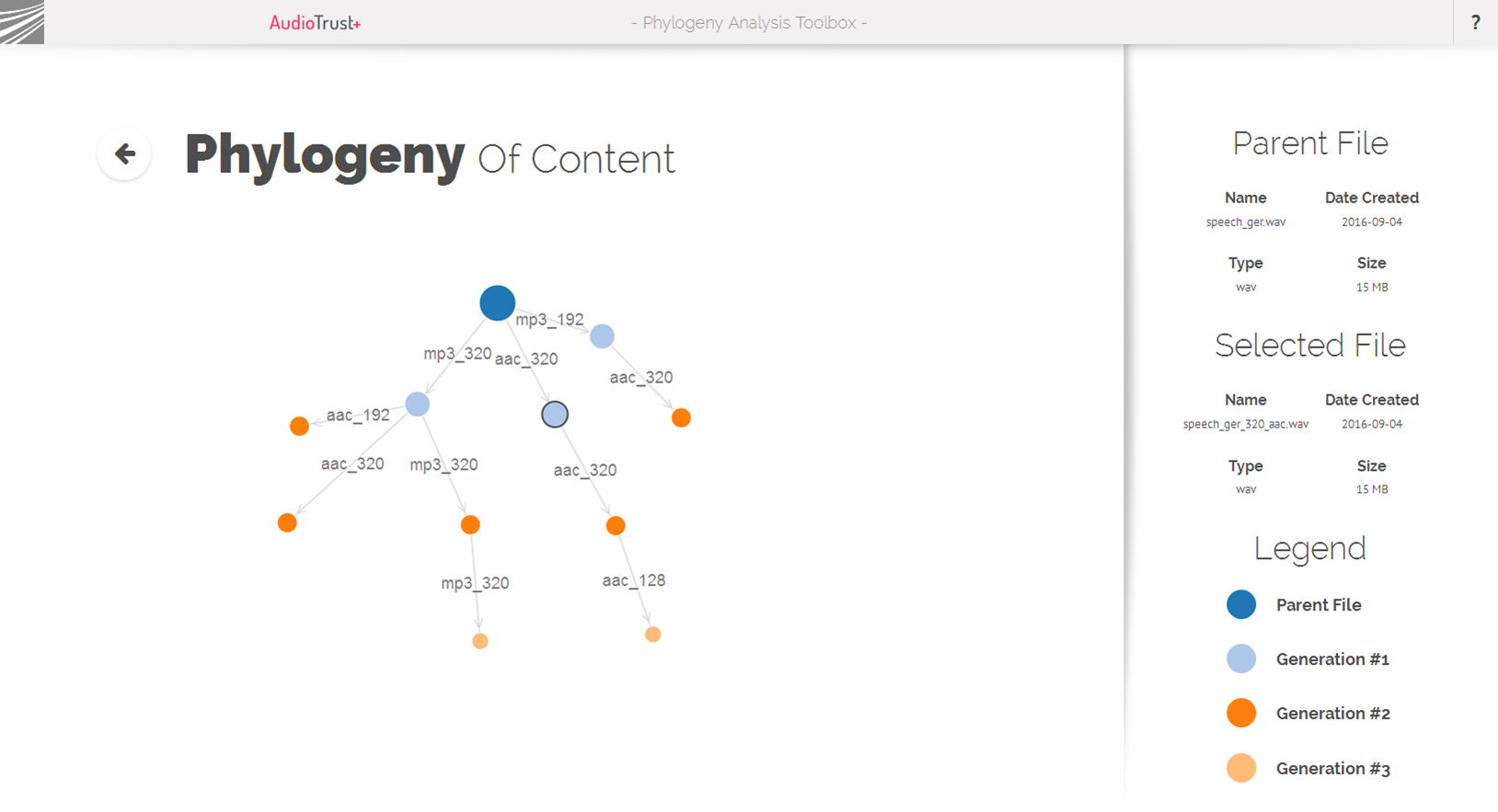 |
The feedback from visitors confirmed that the intended use cases were relevant – we now need to make sure that the activities in all these domains will be continued.
Summary
In summary, IBC proved to be a fruitful event for MICO and our intentions to follow up on the MICO activities. Beyond the many R&D aspects involved, it also became clear that there is a demand regarding consulting interested organizations in their decisions regarding (multi-modal) automatic metadata extraction and related aspects.

 As for general requests regarding the MICO platform, we told all interested visitors that the best time to follow up and to download and try will be in November/December. We promised to provide and update via e-mail by then.
As for general requests regarding the MICO platform, we told all interested visitors that the best time to follow up and to download and try will be in November/December. We promised to provide and update via e-mail by then.