Open Source Named Entity Extraction for the MICO Platform
While their are several Open Source alternatives for Named Entity Extraction (e.g. Stanford NLP, OpenNLP, Freeling) available none of them was initially integrated with the MICO Platform. Instead all Text Extraction capabilities of MICO where backed by the Redlink Platform.
This blog post will present a Open Source alternative for MICO based on OpenNLP and the high quality NER (Named Entity Recognition) models provided by IXA Pipes NERC.
Apache OpenNLP
As from the description of the Webpage:
The Apache OpenNLP library is a machine learning based toolkit for the processing of natural language text.
It supports the most common NLP tasks, such as tokenization, sentence segmentation, part-of-speech tagging, named entity extraction, chunking, parsing, and coreference resolution. These tasks are usually required to build more advanced text processing services. OpenNLP also includes maximum entropy and perceptron based machine learning.
For the extraction of Named Entities one does require the tokenization, sentence segmentation and named entity extraction capabilities.
IXA Pipes NERC extension
Most of the features of OpenNLP are based on machine learning algorithms (max entropy and/or perceptron). All such components need to be configured with models that need to be trained beforehand.
While OpenNLP provides a set of models via its old sourceforge.net homepage those models are more for demonstration purposes. For real world use cases they typically do not provide the required quality.
The IXA Pipes project by the University of the Basque Country provides extensions and high quality Named Entity Recognition models for OpenNLP for Basque, English, Spanish, Dutch, German and Italian.
Note: MICO only provided Debian packages for the bold languages. Packages for other languages can be added by Users. Or the Extractor can also be configured to directly load models from disc.
Language Detection
As OpenNLP (and Named Entity Recognition in general) requires to use different models for different languages one needs to ensure that the language of processed content is known in advance.
To satisfy this requirement a Language Detection Extractor for textual content was also added to the MICO Platform. This extractor is based on the language detection library by Nakatani Shuyo (Cybozu’Labs). It does support 53 languages including all the languages with NER models available.
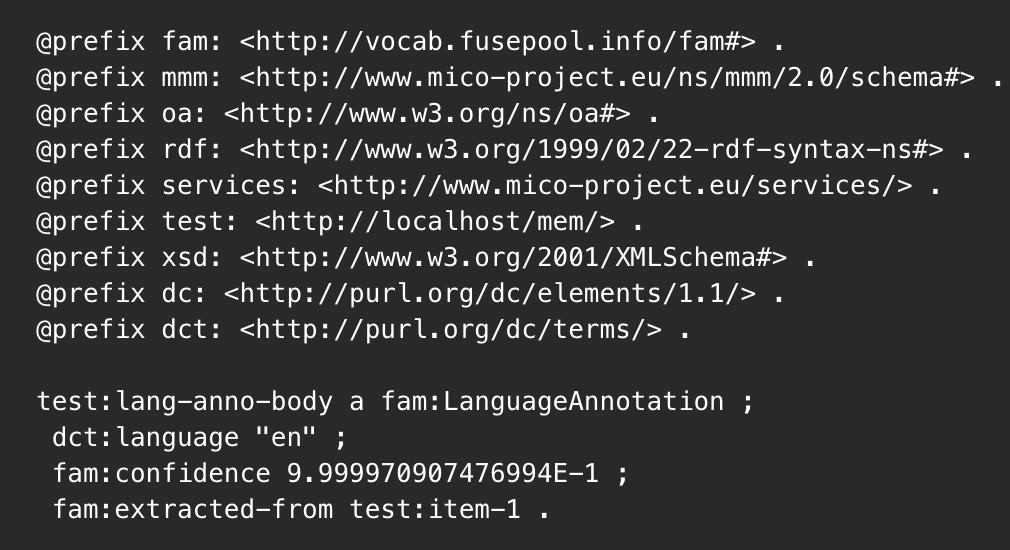
The following listing shows a Language Annotation specifying that the test:asset-1 of the Item test:item-1 is written in English.
@prefix fam: <http://vocab.fusepool.info/fam#> . @prefix mmm: <https://www.mico-project.eu/ns/mmm/2.0/schema#> . @prefix oa: <http://www.w3.org/ns/oa#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix services: <https://www.mico-project.eu/services/> . @prefix test: <http://localhost/mem/> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @prefix dc: <http://purl.org/dc/elements/1.1/> . @prefix dct: <http://purl.org/dc/terms/> . test:lang-anno-body a fam:LanguageAnnotation ; dct:language "en" ; fam:confidence 9.999970907476994E-1 ; fam:extracted-from test:item-1 .
This is the actual Language Annotation as defined by the Fusepool Annotation Model. This defines that the language is English and the confidence of the detection is 99.9997%.
test:item-1 a mmm:Item ; mmm:hasAsset test:asset-1 ; mmm:hasPart test:langdetect-part ; mmm:hasSyntacticalType "text/plain" ; oa:serializedAt "2016-05-25 09:40:30.418" . test:asset-1 a mmm:Asset ; dc:format "text/plain" ; mmm:hasLocation "urn:eu.mico-project:storage.location:item-1/asset-1" .
This defines the Item including a Asset with the text/plain content.
test:langdetect-part a mmm:Part ; mmm:hasBody test:lang-anno-body ; mmm:hasSemanticType "Language Annotation for the plain/text asset" ; mmm:hasSyntacticalType "http://vocab.fusepool.info/fam#LanguageAnnotation" ; oa:hasBody test:lang-anno-body ; oa:hasTarget test:specific-resource-1 ; oa:serializedAt "2016-05-25 09:40:30.755" ; oa:serializedBy services:text-lang-detect . test:specific-resource-1 a oa:SpecificResource ; oa:hasSource test:item-1 .
The remaining RDF is the mmm:Part (also an oa:Annotation) and the other WebAnnotation constructs used to define that this annotation is valid for the whole text.
Tip: as alternative to using language detection it is also possible to already include an according annotation when injection a new Item to the MICO Platform.
The OpenNLP Named Entity Extractor
OpenNLP Named Entity Extraction consists of multiple Debian packages. First the mico-extractor-opennlp-ner package that provides the Extractor and mico-extractor-opennlp-ner-models-model-en, mico-extractor-opennlp-ner-models-model-es, mico-extractor-opennlp-ner-models-model-de and mico-extractor-opennlp-ner-models-model-it providing the models for the given languages.
Users can add additional models by either creating their own debian packages (similar to the existing one) or by directly copying model files to any sub-folder of /usr/share/mico-extractor-opennlp-ner/models. Both normal OpenNLP models as well as models depending on extensions provided by IXA Pipes NERC are supported by the extractor
Example:
The following examples shows the RDF annotation result of the Named Entity “Heinz Fischer” extracted from the German paragraph
Nach seinem knappen Sieg bei der Bundespräsidentschaftswahl wird Alexander Van der Bellen bereits am Dienstag von seinem künftigen Vorgänger Heinz Fischer in der Hofburg empfangen. Am Mittwoch wird der unterlegene FPÖ-Kandidat Norbert Hofer dort erwartet. Die FPÖ will indes in einem Bundesparteivorstand über die Konsequenzen aus der Wahlniederlage beraten. FPÖ-Generalsekretär Herbert Kickl schloss eine Wahlanfechtung nicht aus.
@prefix dc: <http://purl.org/dc/elements/1.1/> . @prefix fam: <http://vocab.fusepool.info/fam#> . @prefix mmm: <https://www.mico-project.eu/ns/mmm/2.0/schema#> . @prefix oa: <http://www.w3.org/ns/oa#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix services: <https://www.mico-project.eu/services/> . @prefix test: <http://localhost/mem/> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . test:named-entity-1 fam:entity-mention "Heinz Fischer"@de ; fam:entity-type <http://schema.org/Person> ; fam:extracted-from test:item-1 ; fam:selector test:text-selector-1 ; a fam:EntityMention .
This is the Entity Mention Annotation as defined by the Fusepool Annotation Model. It defines the mention, the type and links to the selector and the content the entity was extracted from.
test:text-selector-1 a oa:TextPositionSelector ; oa:end "154"^^xsd:long ; oa:exact "Heinz Fischer" ; oa:prefix "nger " ; oa:start "141"^^xsd:long ; oa:suffix " in d" .
This is a combined oa:TextPositionSelector and oa:TextQuoteSelector that defines the selection by both char offsets as well as prefix/exact/suffix. The later is especially important if the input text was a rich text document as in such cases char offsets are not very useful to re-locate the selected part of the text in the original document.
test:named-entity-part-1 mmm:hasBody test:named-entity-1 ; mmm:hasInput test:item-1 , test:lang-annotation-part-1 ; mmm:hasSemanticType "Named entity recognized in the input text file" ; mmm:hasSyntacticalType "http://vocab.fusepool.info/fam#EntityMention" ; a mmm:Part ; oa:hasBody test:named-entity-1 ; oa:hasTarget test:text-selector-1 ; oa:serializedAt "2016-05-25 13:13:48.121" ; oa:serializedBy services:opennlp-ner . test:specific-resource-1 a oa:SpecificResource ; oa:hasSelector test:text-selector-1 ; oa:hasSource test:item-1 . test:item-1 mmm:hasAsset a mmm:Item ; test:1ecc5de5-906e-45a8-87f4-716259b57ce5 ; mmm:hasPart test:named-entity-part-1 , [..]; mmm:hasSyntacticalType "text/plain" ; oa:serializedAt "2016-05-25 13:13:47.573" .
The rest of the RDF describes the mmm:Item, the mmm:Part representing this annotation and some other required OpenAnnotation classes.
As the RDF annotation are fully compatible to those generated by the MICO Extractor based on the Redlink Platform this extractor can be used as an 1:1 Open Source replacement in existing Usage Scenarios that require Named Entity Extraction.