MMM – MICO Metadata Model Version 2
The MICO Metadata Model (MMM) is an RDF model with the purpose of describing a multimedia item in in combination with its (extracted) metadata background. Therefore, it adopts the W3C Web Annotation Data Model‘s structure and idea of an “annotation” – an entity that describes or further specifies another thing. They define it as a piece of further description (e.g. marginalia or highlight) for a digital resource like a comment or tag on a single web page or image, or a blog post about a news article. The MMM broadens the context of annotations to a multimedia workflow-driven use case by allowing the combination of different annotations to form the metadata background of given multimedia items.
A lot has changed during the last iteration of the metadata model. Many lessons learned have led to insights and new experiences in terms of designing an RDF model, whose purpose is to subsume different extraction results under one single denominator. From this point, improvements have been made to the model in order to make it more lightweight and adjusted to its intention. Next to this, some new features have been added, like for example provenance information is now supported in a more detailed way.
In this blogpost, we illustrate the most significant changes. Before going into detail, it is important to mention that we decided to split the model into different vocabularies. The basic concepts of the model that enable the implementation of a multimedia file in combination with its metadata background accompanied by provenance information builds up the basis of the MICO Metadata Model (MMM). Its documentation can be found here, while its formal specification is located here.
A split was made to separate the core functionality from the MICO specific additions. In this context, the MICO Metadata Model Terms vocabulary was created, which includes ways of describing the output produced by the various extractors in the MICO use case. Its documentation can be found at here and its formal specification here. The abbreviations of the namespaces were transformed from mico to mmm for the base concepts, and mmmterms for the MICO specific vocabulary.
Aggregation of Key Concepts
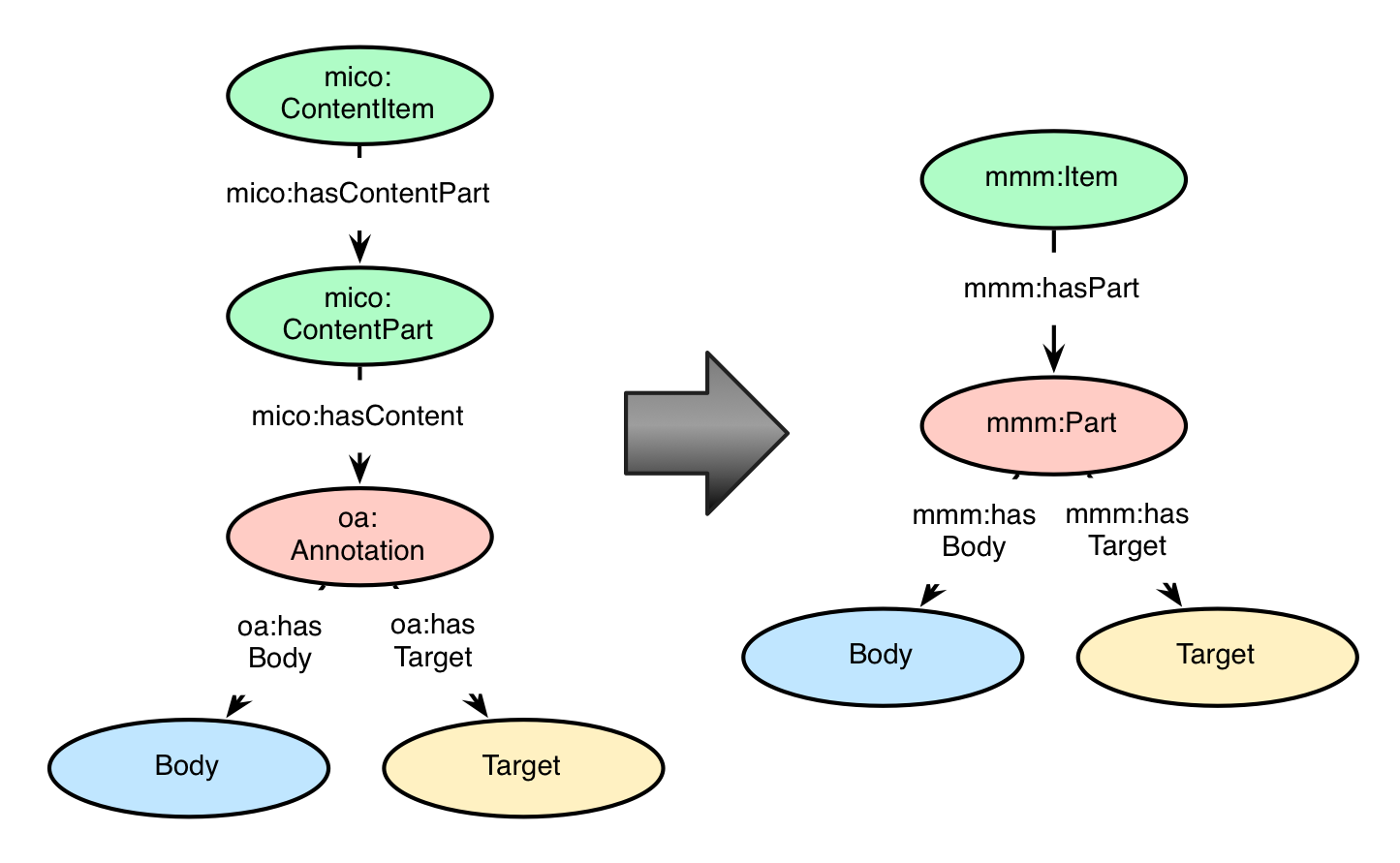
The former model version featured a three-layer concept hierarchy “above” the actual metadata, namely ContentItem, ContentPart, and Annotation. As there were two entities that were kind of redundant, we decided to flatten this part of the model by removing one layer and also apply a change of names. The former ContentItem is now simply known as an Item, which corresponds to the multimedia file that is ingested and analysed at the MICO platform. ContentPart and Annotation (and all of its associated information) are merged together, now being called a Part. A Part symbolises an extraction step of a workflow and therefore it corresponds to a “part” of the Item’s metadata background. Additionally to this, the mmm:Part class inherits from the WADM’s class oa:Annotation, keeping the specification’s concept and idea of an Annotation.
Improved Media File Information
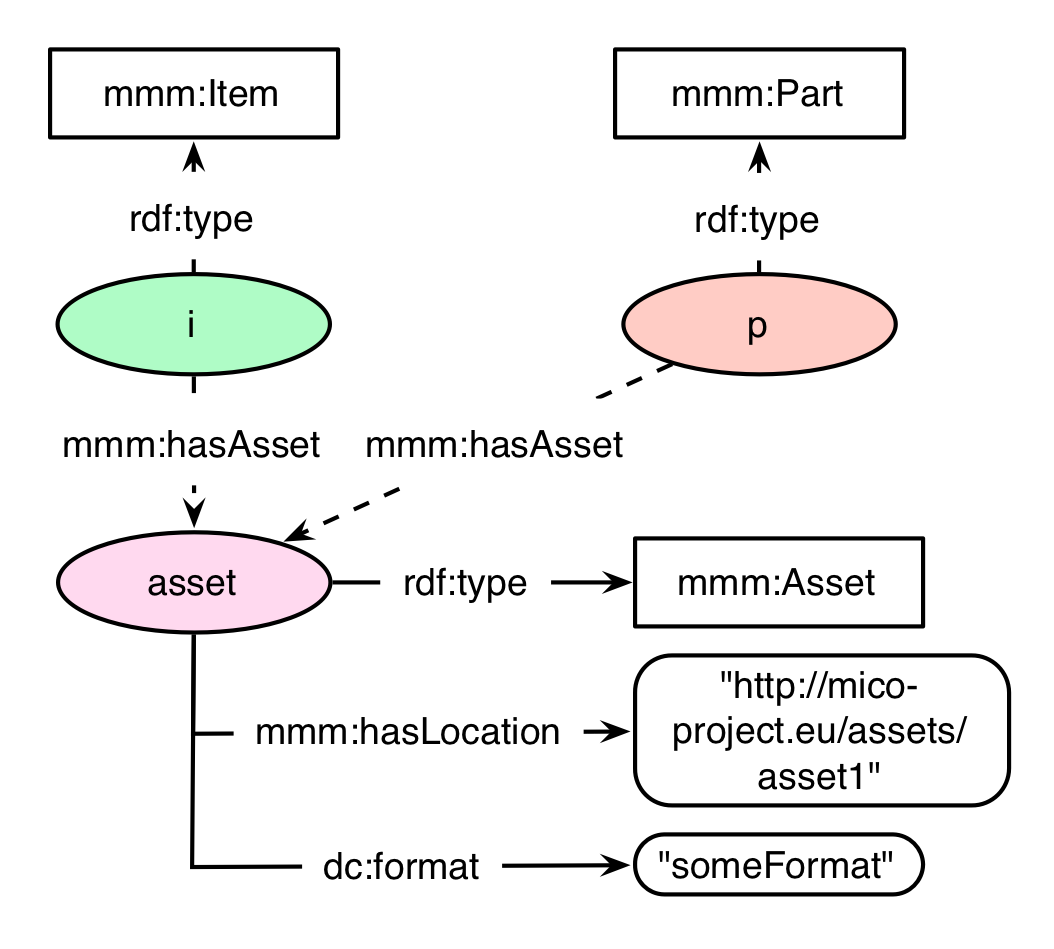
Media files in the MICO platform context are associated either by the ingestion of an initial media file into the platform, or as a result of an extraction step. The former model version copiously realised this by implementing an own annotation. Version 2 of the MMM implements this by introducing the RDF class mmm:Asset. By supporting the multimedia file’s physical location and its format, the asset symbolizes the multimedia files in the MICO workflow. An asset can be associated with an mmm:Item or a mmm:Part respectively.
Improved Provenance Information
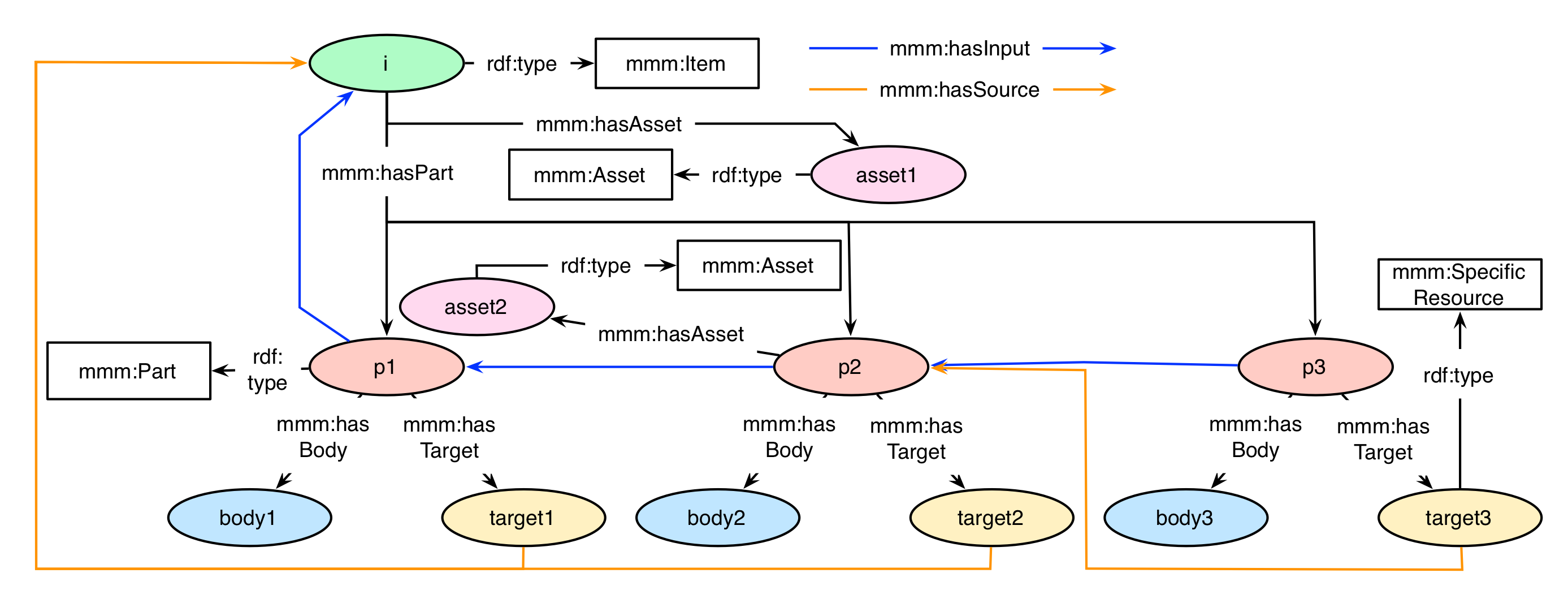
As provenance information is a very important aspect in a workflow-driven environment like the MICO platform, the importance should also be matched equally in the underlying RDF model. Two relationships of a given mmm:Part instance support this: mmm:hasSource and mmm:hasInput. The source of an annotation relates to the multimedia file to which the annotation is associated to. The edge mmm:hasSource is still attached (as in the previous model) to the mmm:SpecificResource associated with the given part. The input of a Part resembles the actual metadata that is needed in order to create the actual annotation. Consider following examples:
-
- A video (asset1 associated with Item i) is ingested in the MICO platform. A shot detection process detects the shots of the video, creating that information in a Part (p1). As the extraction is done directly on the video, and the “information” needed to create the annotation is also the video itself, both the source and input edges of p1 are directed to i.
-
- From the shot segmentation, a second extractor identifies the most important picture – the keyframe – of a given shot (p2). As this is based on the video, but the actual information is contained in the first extractor’s result (p1), the source is directed from p2‘s SpecificResource to i, while the input edge is directed from p2 to p1.
- The third and last extractor detects faces on pictures. So this extractor can use the information of the second extractor and creates a Part (p3) that contains the extracted face’s information. This annotation is based on a picture (asset2), its information input is also the picture, so here both the source and input edges are directed from p3 to p2.
This exemplary workflow is depicted in the following graph. Some details (e.g. the information of the bodies, targets, or assets) are omitted for the sake of clarity. This shows the relatedness of the different extraction results (instances p1, p2, and p3 in red), combined under their superior mmm:Item (instance i in green).
Minor Changes
In addition to the mentioned major changes, smaller adaptions to the model have been made to support its usability. Some relationships have been adjusted in terms of their multiplicities.
Introduction of mmm:Resource
A class mmm:Resource distinctively subsumes the classes mmm:Item and mmm:Part in order to more easily regulate various relationships or multiplicities, e.g. the relationship mmm:hasAsset and the provenance edges mmm:hasInput and mmm:hasSource.
Inherited WADM Classes, Relationships and Properties
Many classes, relationships, and properties of the Web Annotation Data Model have been adapted and inherited in our model. All of them fulfill the same role as they do in the WADM, but the implementation in our model required some adjustment in terms of the multiplicities. For example, the WADM allows an annotation instance to support multiple bodies, which does not correspond to our workflow-driven environment. In MICO, every Part has exactly one body instance.
Superclass mmm:Body
As it is reasonable to support a type for all the body instances that are utilized for various extraction steps (in order to distinguish for example a face detection from an animal detection by type), version 2 of the MMM implements a superclass mmm:Body for all the various body classes. This superclass and all its inherited classes are very useful in terms of querying.
Future Work
Possible additions to the MMM during the course of MICO will be added as modules:
-
- Extractor Provenance and Broker Enhancements: Improved implementations and design patters for both the extractors and the broker component of the MICO workflow open new possibilities and will add to a more profound implementation of the whole platform. Extractors can be started in various settings to be more fine-tuned to its associated input. A new broker version can support workflow planning and design. All of this will form a new model module, prepared for the next model version.
- Recommendation: For some MICO use cases and also the general annotation design one could envision a recommendation process that, given an annotation or its content, recommends similar content. Reification is a promising RDF concept which could be utilised to implement recommendation on mmm:Resource level.
Main Contributors
- Emanuel Berndl (University of Passau)
- Kai Schlegel (University of Passau)
- Andreas Eisenkolb (University of Passau)
For more detailed information please visit the documentation of the MMM here or the MMMterms here.