(Emanuel Berndl, University of Passau, PhD Thesis – Early Ideas)
Thematically, the thesis is set in the field of the Semantic Web, whose idea is to make data in the web be more usable and “understandable” in a wider context through the utilisation of metadata. This metadata is used in order to store and support more information about its corresponding data object, whether it is for example a video, image, text, audio, or even raw data. But there exist many problems to bring this vision to life. A lot of metadata is produced, but in many cases, those data silos are only working in isolation, a combined knowledge base is rarely created. Next to this, most of the silos implement their metadata using their own language, proprietary (RDF) formats are used. Another problem lies in the Semantic Gap:
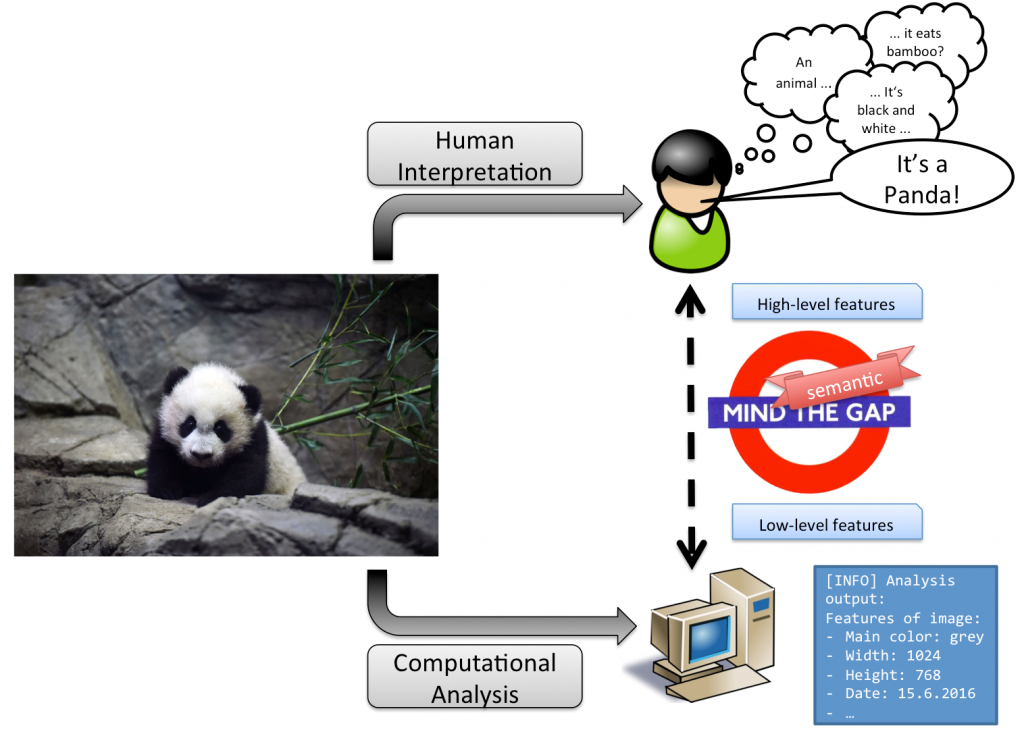
The semantic gap: Differing interpretation between humans and machines
The Semantic Gap illustrates the problem of divagating “interpretation” of the same multimedia item between humans and machines. For example, when interpreting the image of the figure above, humans can use their past experiences and their context awareness in order to detect the information – so called high-level features are utilised. In contrast, a machine can only use raw data that can be extracted from the image. In this example, the machine can detect and accumulate colors of pixels, detect edges, or assert structural data of the image like width and height. These are called low-level features – information that is merely enough to really “understand” the information or the “meaning” of the given multimedia item. The already mentioned problems of the allocation and use of proprietary formats even aggravate the gap. Even if there would be data about one given media object in different knowledge bases, the combination – and as a result combined interpretation – is out of scope.
As a (partial) solution to these problems, the main contribution of the thesis is the RDF ontology called the MICO Metadata Model MMM (see the MMM specification, or the paper “A platform for contextual multimedia data: towards a unified metadata model and querying” [1]), which was the major output of workpackage 3 of the MICO project and myself. It is an extension to the Web Annotation Data Model WADM (see WADM specification), adding a layer of interoperability to the main concept of the WADM: the Web Annotation. A Web Annotation is used in order to express information about a given multimedia item, depicting marginalia or highlights in pictures, videos, audio streams, web pages, or even raw data. This information unit is built out of three core elements:
- The Body node contains the actual information that is to be conveyed.
- The Target node specifies the item that the information is about, the WADM states that “the body is somehow about the target”.
- An Annotation node joins the body and the target, and may contain various provenance descriptions.
The MMM uses the concept Web Annotations and shifts its meaning to a workflow-driven context, to make them applicable for cross-media processing. Web Annotations are interpreted as intermediary and final results of extractors that jointly analyse one given multimedia item. The layer that is added by the MMM can now connect various Annotations together, as different extractors add bit by bit, to form a combined metadata background. Provenance information like tracing of the extraction workflows and utilisation of metadata information for subsequent analysis processes is also supported by the MMM.
Using this ontology as the main pillar, a three-step workflow/cycle is envisioned with the aim of creating, consuming, and exploring metadata for given multimedia items in order to make them usable in a Semantic Web context.
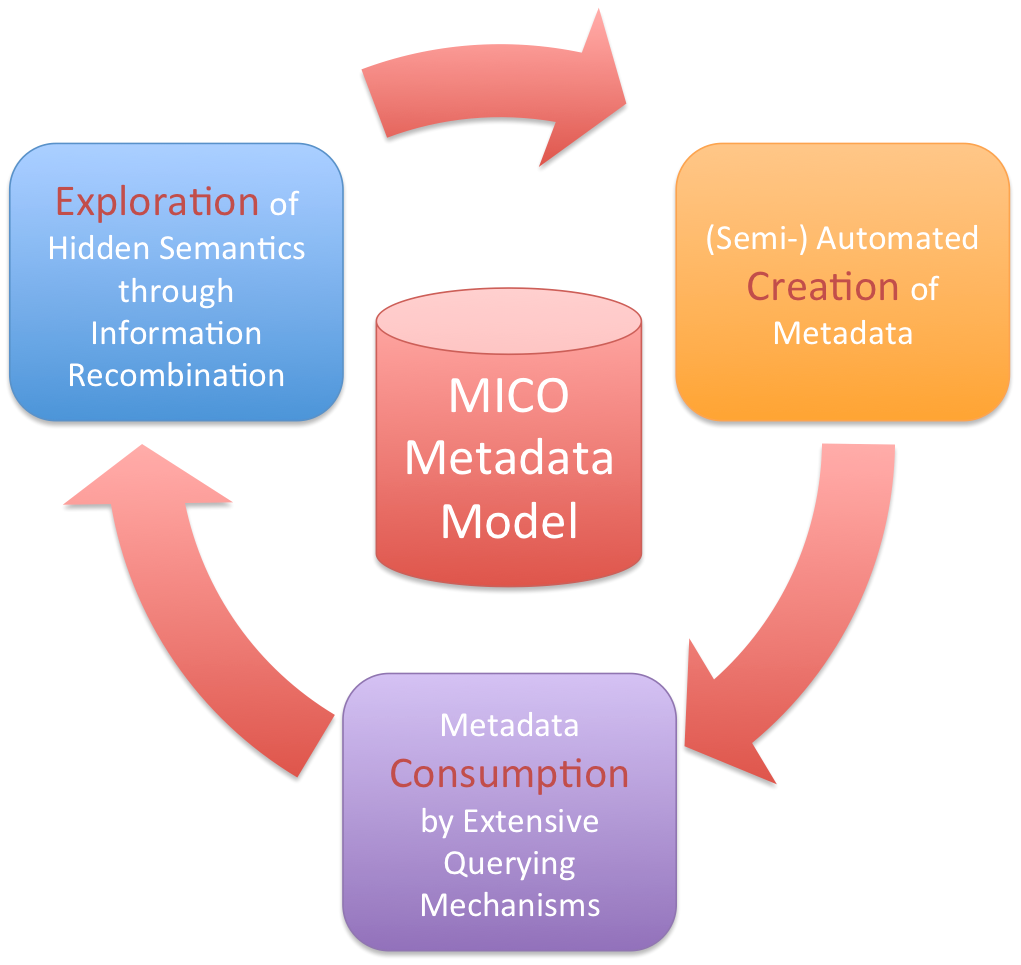
Three-step metadata workflow
Utilising the workflow, and especially its output, the injected multimedia items are to be semantically enriched, which means that next to the data itself, metadata will be extracted and stored alongside. Making use of the MMM, metadata from different silos can be used. Additionally, as it is a cycle, it is possible to have several iterations of the three steps, as results of one extraction chain can trigger other analysis processes and accordingly produce further information. This metadata possibly makes the given multimedia item usable in up to now unknown contexts. Imagine the possibility of a semantic search, not searching for text strings that (partially) match a given title, but rather the search for concepts that appear in multimedia files. The classic MICO example is the semantic search for dog, which returns videos and images that semantically contain dogs – information that is produced by (combined) extraction processes.
The MICO platform, the central software contribution of the MICO project and its consortium, is a perfect technical setting for this thesis and will be highlighted as that. Other technical contributions will also influence this work. Anno4j (also see the paper “Idiomatic Persistence and Querying for the W3C Web Annotation Data Model” [2]) is a Java-based read and write API for RDF, which supports an Object-RDF-Mapping and therefore enables the Creation and Consumption parts of the envisioned workflow, and will therefore also form a core contribution of the thesis. The evaluation part, presumably featuring different experiments with the presented RDF ontology and workflow in order to generate quantifiable results, is not yet designed or sketched.
References
[1] K. Schlegel, E. Berndl, M. Granitzer, H. Kosch, and T. Kurz, A platform for contextual multimedia data: towards a unified metadata model and querying, in Proceedings of the 15th International Conference on Knowledge Technologies and Data-driven Business, i-KNOW 2015.
[2] E. Berndl, K. Schlegel, A. Eisenkolb, and H. Kosch, Idiomatic Persistence and Querying for the W3C Web Annotation Data Model, in Joint Proceedings of the 4th International Workshop on Linked Media and the 3rd Developers Hackshop co-located with the 13th Extended Semantic Web Conference ESWC 2016, Heraklion, Crete, Greece, May 30, 2016.