The MICO Platform at its core provides access to a collection of extractors to analyse “media in context” by orchestrating them with the support of basic features required in the process (media and metadata storage, messaging and querying). The technical foundations behind this platform are extensively described in deliverables “System Architecture and Development Guidelines” (D6.1.1) and “Platform: Initial Version” (D6.2.1), and the source code available from our repository.
In the first year of MICO we focused on implementing an initial version of the platform. Rather than iteratively design each component we considered in an agile manner the complete workflow required for storage extractors’ registration, orchestration and querying. For some components , such as SPARQL-MM, we had clear requirements and much more experience on the technology involved, so such components are considered more stable and usable form the very first versions. For the other components we had to find a balance between functionality and time required, both in terms of requirements and development effort.
Therefore the first version of the platform released on October 2014 contained a few experimental components covering a rather small subset of features. Two of those components where the broker and the storage: the first addressed the orchestration problem in a very simplistic scenario, this was needed to better understand the functional requirements; while the second was implemented using FTP as a basic solution, which lacks many required features regarding distribution and replication. Although the final decisions are still outstanding, we can anticipate that the project will choose Apache Camel and HDFS to help us solve the above challenges.
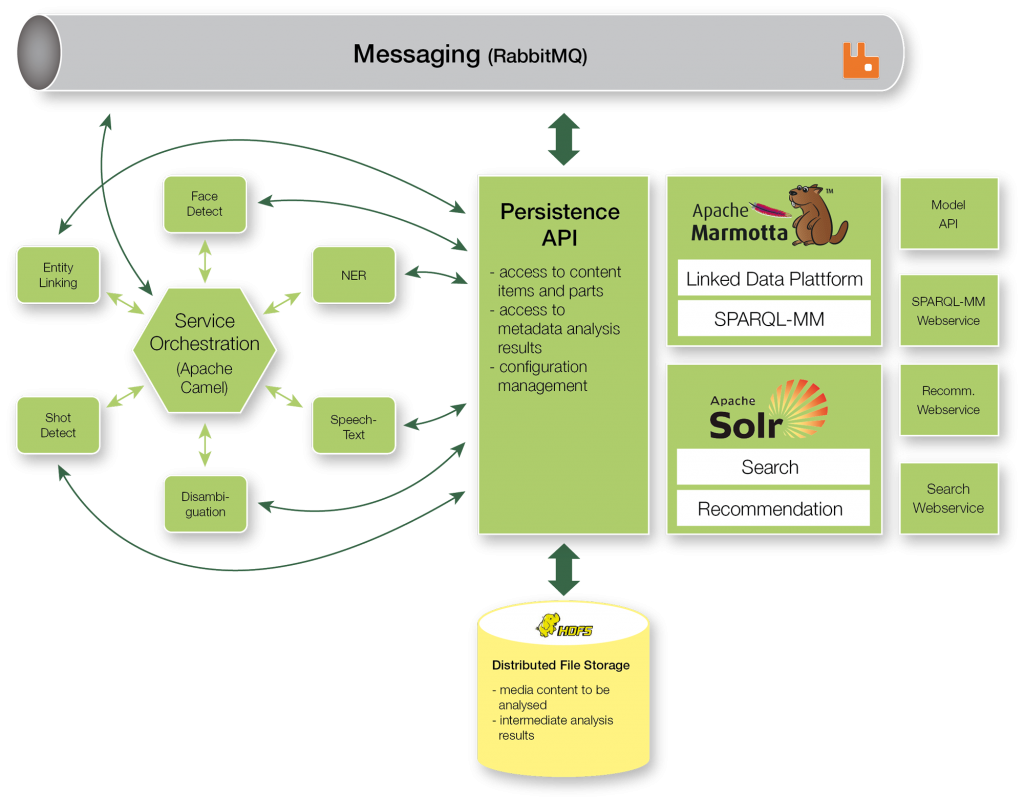
In the next phase of development the platform will address the requirements raised in the use cases. This includes how to integrate the recommendation components that bring more context related information to the platform. And, how to evolve the testability of the platform, both at the low-level (each extract would need to come with its unit tests) and high-level (human validation of the overall process).
New branches are already being setup for the first prototypes of all these features, and we hope such tasks development will produce results of quality that will be available before the next milestones.