The MICO platform is an ambitious research and development project to realize the value of cross-media analysis and querying in a number of use cases. At the end of 2014 the first specifications for the MICO platform was published. You can access or download your copy from the publications section. But before we look at the main results, lets quickly revisit the requirements process that forms the basis of the specifications.
Use Case Requirements
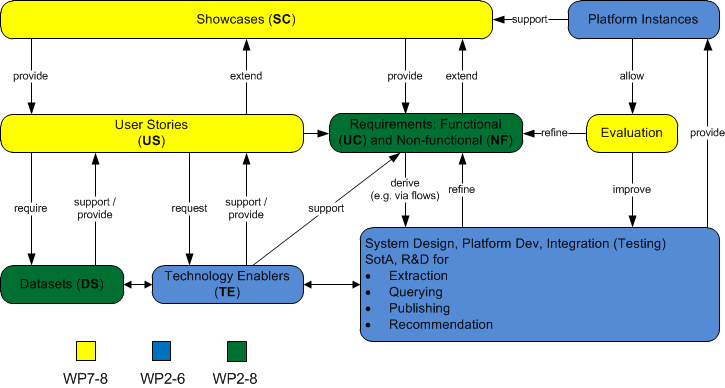
MICO methodology
The requirements analysis process took place in the first half of 2014. For the full explanation of the requirements methodology applied in MICO see the blog post “Waterfagile requirements analysis in MICO”
Showcases (SC) are the main starting point for requirements analysis. While not representing requirements as such, MICO showcases represent current or planned projects of Zooniverse (ZOO) and InsideOut10 (IO). They provide the context for all further requirements, and represent slightly different combinations of goals, content sets, and user communities involved. The total of 9 showcases as potential “targets” for the MICO project, were further prioritized into two groups considering
- expected impact and industrial, scientific, and societal value
- variety and volume of cross-media content
- existence of “MICO aspects”, e.g. potential of accuracy and robustness improvements due to cross-modal analysis
- technical feasibility regarding availability of textual and audio-visual media extraction, publishing, querying, recommendation technologies, and cross-cutting technical platform requirements
Cross-media analysis in the citizen science platform Zooniverse.

“The data in each of these projects consists of images with associated metadata. Users have the ability to comment on any image they see, leading to a large source of associated textual information for many of the images. MICO technologies will be applied to at least one of the projects, leading to an efficient classification interface that provides the user with more relevant information, in turn helping speed up the data analysis and allowing the scientists to uncover important results faster.”
Cross-media analysis in the news and media sector.
Here below Insideout Today CEO Fady Ramzy presenting MICO at the Mashable Social Media Day in Cairo.
Fady Ramzy from @InsideOut_Today speaking now in #SMDayEgypt @CyberZizo #Twitter #Mashable pic.twitter.com/sFX1RBVmLr
— Mina Shawky (@minashawky) June 21, 2014
First Specifications in Cross-Media Analysis, Metadata Publishing, Querying and Recommendations
 The specifications document is arranged according to the main components of the MICO platform: cross media analysis, metadata publishing, querying and recommendations. A short summary of the four sections is provided below. For the complete document please visit the Publications Section, or alternatively you can follow this link for the PDF document. The specifications will be updated in the next round of development and validation phases that will take place in the first half of 2015.
The specifications document is arranged according to the main components of the MICO platform: cross media analysis, metadata publishing, querying and recommendations. A short summary of the four sections is provided below. For the complete document please visit the Publications Section, or alternatively you can follow this link for the PDF document. The specifications will be updated in the next round of development and validation phases that will take place in the first half of 2015.
- Cross-media Analysis: A number of media extractors have been selected for the validations of the showcases described above. A full list of the media extractors available to MICO is available at: https://www.mico-project.eu/technology/. The extractors in focus for the next phase of development and validation are: Low level Feature Extraction; Face Detection and Recognition; Object and Animal Detection; A/V Error Detection and Quality Assessment; Temporal Video Segmentation; Visual Similarity; Speech Music Discrimination; Audio Cutting Detection; Media Container Tag Extraction; Named Entity Recognizer; Phrase Structure Parser; Automatic Speech Recognition; Sentiment Analysis; Chatroom Cleaner; Interactive Wrapper Generator; Textual Feature Extraction; and Query Detection;
- Cross-media Metadata Publishing: Every workflow and extraction process of the MICO platform will end in accumulations of information, which will for example consist of annotations, multimedia files, or their provenance information. All of this has to be stored and treated in a uniform way, which also allows the saved data and information to be accessible afterwards. For that reason, we developed a metadata model that will cover all of the aspects. A first version of the metadata model is presented. At its core, it provides a standard ontology for publishing metadata based on several existing ontologies, adapted and extended to the MICO requirements, now available at https://www.mico-project.eu/ns/platform/1.0/schema# and complements by an annotation design based on the Open Annotation Data Model, including examples.
- Cross-media Querying: One of the key innovations that MICO is working on is how to query cross-media analysis results. The approach in MICO is to use a semistructured format (namely RDF) which gives the possibility to easily extend and adopt the model to current and upcoming use cases. With SPARQL we have a standardized query language for this kind of data structure, which is very powerful regarding expressivity but lack specific features that are necessary for a proper multimedia (Meta-) data retrieval. Here we introduce SPARQL-MM as an extension for the de-facto standard query language in the Semantic Web world (SPARQL), which aims to bridge this gap by introducing special features like fulltext-search and spatio-temporal filter and aggregation functions.
- Cross-media Recommendations: Along with cross-media querying, recommendation solutions will be used to track the activity of the users in terms of their interactions with the content managed by MICO for suggesting unknown content in the platform that could be interesting for the user. For Zooniverse, the interaction data will consist of the users actions over the images or subject: classification and comments. For the news media use case interaction data includes: like/dislike; ratings, and content interaction based on context.