Enterprises today are mostly content intensive and knowledge driven. On a daily basis enterprises generate large amounts of content in different formats such as text documents, images, audios and videos in day to day business. According to Gartner about 80-90% of the enterprise knowledge resides in these unstructured content. Unstructured content comprises of text documents such as emails, business contracts, marketing documents which are written in natural language narrative and multimedia files that don’t conform to any predefined data model or structure but contain vital knowledge. Unveiling the hidden knowledge in these unstructured content and multimedia files has become a huge challenge in the enterprise today.
Searching relevant documents with accuracy and efficiency is another major challenge in the enterprise. For successful business operations, it is essential that the knowledge workers can quickly locate relevant content and have access to the required knowledge to take necessary action when completing a business task or solving a problem in their daily activities. Therefore findability of information and knowledge discovery from unstructured content have become key success factors in knowledge driven enterprises.
Enterprise Search is considered as the main solution to finding information and discovering knowledge in the enterprise. It can provide a federated search across all the content repositories in the enterprise. With the emergence of linked-data and semantic web techniques, enterprise search has been largely benefited with advance semantic search features beyond simple keyword search. Unstructured content can be enhanced with additional knowledge using semantic web and linked data techniques by annotating documents with related named entities and other semantic meta-data (eg: temporal data, geo-spatial data etc.). Further these content can be linked with external knowledge-bases (eg: DbPedia, Freebase or enterprise specific knowledge-bases) leveraging linked-data to give more context to the documents. This paves way to advance semantic search techniques such as entity driven search and concept driven search where users can find what they are looking for, intuitively with context. Autocomplete of search queries can be enhanced with suggested entities instead of just keywords guiding users to what they are looking for, in an intuitive manner. Leveraging relationships among the named entities in the documents and linked data, knowledge graphs can be constructed giving more context and machine-readable structure to the content, improving search efficiency and accuracy.
However, these semantic search features have been mostly limited to text content. Semantic search across all media has not been possible, mainly because there was no standard semantic annotation model for multimedia content. This is where we plan to integrate MICO with an available open source enterprise search platform to leverage the power of cross media search in the enterprise context.
Sensefy
As the enterprise search framework for MICO integration, we plan to use Sensefy. Sensefy is an enterprise semantic search engine developed by Zaizi. Built on top of leading open source software, it provides users with advanced enterprise search functionalities. Sensefy is enterprise because it offers federated search, with the capabilities to index content from heterogeneous data sources while preserving the access control lists (ACL) of the source repositories. Only the permitted users are able to search and access the content. Sensefy is semantic because it enriches the documents semantically to extract entities such as people, organizations and places and improve the user’s search experience by providing intelligent search functionalities.
Sensefy-MICO Integration
By integrating MICO with Sensefy, we aim to facilitate search users to semantically search related content across all media in the enterprise. We also plan to implement cross media recommendations to recommend related content to the search user based on his past search queries. The high-level of Sensefy-MICO integration is given below.
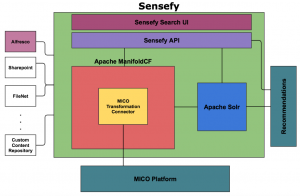
High-level architecture: Sensefy MICO integration
Components
Following sections describe the components of our architecture to integrate MICO with Sensefy.
Apache ManifoldCF
Central to the Sensefy is the Apache Manifold Connector Framework. ManifoldCF functions as the content crawler of Sensefy framework. ManifoldCF provides a set of pluggable connectors for connecting with different content repositories, indexing in different search servers and a crawler that can be run by scheduling jobs. There are three main types of connectors in ManifoldCF.
- Repository Connectors – Allows you to connect to content repositories for crawling purposes.
- Transformation Connectors – Allows you to transform content fetched from repositories before indexing into search servers. Currently Sensefy framework provides a Tika connector for metadata extraction, OpenNLP connector for extracting named entities, Stanbol Connector and meta data mapping connector that maps input fields to output fields.
- Output Connectors – Allows you to index documents, metadata and permissions in different search servers (indexes). Currently provide connectors for popular search servers such as Solr, Amazon CloudSearch and ElasticSearch.
MICO Transformation Connector
In this Sensefy-MICO integration project, we plan to implement a transformation connector to connect to MICO platform and retrieve multimedia metadata of the documents passed through ManifoldCF. MICO transformation connector will submit the documents to MICO platform as documents are passed through the connectors chain and will retrieve analyzed metadata by querying the Triple Store via Anno4j / Sparql. This connector will be contributed to the ManifoldCF community.
Apache Solr
Solr search server is used as the backend search server. Sensefy supports both SolrCloud and single server. Although it is possible to use other search servers such as elastic search and Amazon CloudSearch as the backend, Sensefy Search API currently only supports Apache Solr.
Content repositories
Alfresco ECM (Enterprise Content Management) system is considered as the primary content repository. Sensefy is currently fully tested against both Alfresco 4 and Alfresco 5 versions.
The great advantage of using Sensefy as the search platform to exploit MICO technology to provide enterprise cross media search is that Sensefy has the capability of connecting heterogeneous content repositories other than just Alfresco such as SharePoint, FileNet, Confluence, FileSystem etc. Future versions of Sensefy will support these different repositories and thereby reaching to a wider audience of enterprise users.
Sensefy API
Sensefy API will be extended to support cross media search and recommendations using MICO API.
Sensefy UI
Sensefy UI will be extended to support cross media semantic search and recommendations. Search users will get entity suggestions for search autocomplete as below.
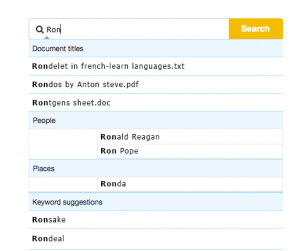
Entity suggestions for search autocomplete
Search results will contain all types of media files which are annotated with the searched entity as below.
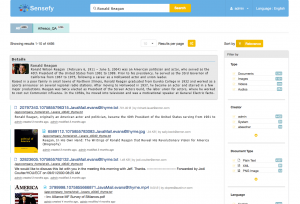
Cross media entity driven search results
We are excited about the new cross media search feature in Sensefy, which is possible due to MICO platform. We will keep you posted on the development of this project in the next few months. Stay tuned for more updates on Enterprise Cross Media Search using MICO !