We’ve finally reached an important milestone in our validation work in the MICO project…we can begin testing and integrating our toolset with the first release of the platform to evaluate the initial set of media extractors.
This article was originally posted on the Insideout10 Blog
This blog post is more or less a diary of our first attempts in using MICO in conjunction with our toolset that includes:
- HelixWare – the Video Hosting Platform (our online video platform that allows publishers and content providers to ingest, encode and distribute videos across multiple screens)
- WordLift – the Semantic Editor for WordPress (assisting the editors writing a blog post and organising the website’s contents using semantic fingerprints)
- Shoof – a UGC video recording application (this is an Android native app providing instant video-recording for people living in Cairo)
The workflow we’re planning to implement aims at improving content creation, content management and content delivery phases.
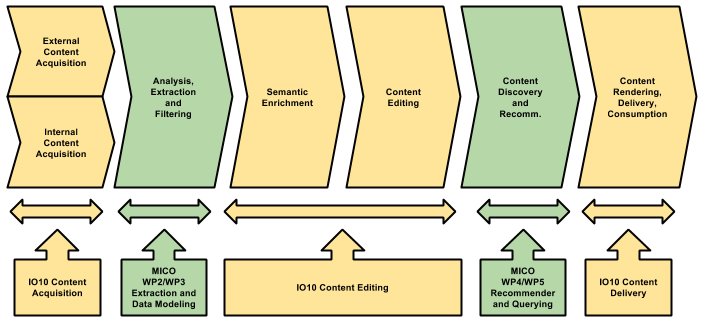
The diagram describes the various steps involved in the implementation of the scenarios we will use to run the tests. At this stage the main goal is to:
- a) ingest videos in HelixWare,
- b) process these videos with MICO and
- c) add relevant metadata that will be further used by the client applications WordLift and Shoof.
While we’re working to see MICO in action in real-world environments the tests we’ve designed aims at providing valuable feedback for the developers of each specific module in the platform.
These low-level components (called Technology Enablers or simply TE) include the extractors to analyse and annotate media files as well as modules for data querying and content recommendation. We’re planning to evaluate the TEs that are significant for our user stories and we have designed the tests around three core objectives:
- output accuracy how accurate, detailed and meaningful each single response is when compared to other available tools;
- technical performance how much time each task requires and how scalable the solution is when we increase in volume the amount of contents being analysed;
- usability evaluated both in terms of integration, modularity and usefulness.
As of today being, everything still extremely experimental, we’re using a dedicated MICO platform running in a protected and centralised cloud environment. This machine has been installed directly by the technology partners of the project: this makes it easier for us to test and simpler for them to keep on developing, hot-fixing and stabilising the platform.
Let’s start
By accessing the MICO Admin UI (this is accessible from the `/mico-configuration` directory), we’ve been able to select the analysis pipeline. MICO orchestrates different extractors and combines them in pipelines. At this stage the developer shall choose one pipeline at the time.
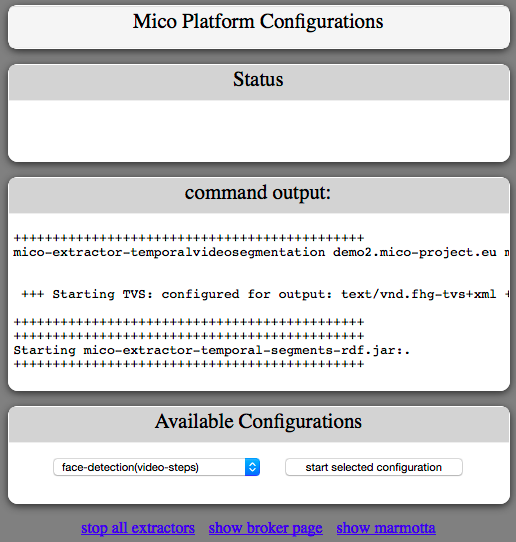
Upon startup we can see the status of the platform by reading the command output window; while not standardised this already provides an overview on the startup of each media extractor in the pipeline.
For installing and configuring the MICO platform you can read the end-user documentation: at this stage I would recommend you to wait until everything becomes more stable (here is a link to the MICO end-user documentation)!
After starting up the system using the platform’s REST APIs we’ve been able to successfully send the first video files and request the processing of it. This is done mainly in three steps:
1. Create a Content Item
| Request |
| curl -X POST http://<mico_platform>/broker/inject/create |
| Response |
| {“uri”:”http://
<mico_platform>/marmotta/322e04a3-33e9-4e80-8780-254ddc542661″} |
2. Create a Content Part
| Request |
| curl -X POST “http://
<mico_platform>/broker/inject/add?ci=http%3A%2F%2Fdemo2.mico-project.eu%3A8080%2Fmarmotta%2F322e04a3-33e9-4e80-8780-254ddc542661&type=video%2Fmp4&name=horses.mp4″ –data-binary @Bates_2045015110_512kb.mp4 |
| Response |
| {“uri”:”http://
<mico_platform>/marmotta/322e04a3-33e9-4e80-8780-254ddc542661/8755967a-6e1d-4f5e-a85d-4e692f774f76″} |
3. Submit for processing
| Request |
| curl -v -X POST “http://
<mico_platform>/broker/inject/submit?ci=http%3A%2F%2Fdemo2.mico-project.eu%3A8080%2Fmarmotta%2F322e04a3-33e9-4e80-8780-254ddc542661″ |
| Response |
| HTTP/1.1 200 OK
Server: Apache-Coyote/1.1 Content-Length: 0 Date: Wed, 08 Jul 2015 08:08:11 GMT |
In the next blog posts we will see how to consume the data coming from MICO and how this data will be integrated in our application workflows.
In the meantime, if you’re interested in knowing more about MICO and how it could benefit your existing applications you can read:
- the combined use cases prototypes: the application scenarios where MICO will be used
- the combined use cases test plan: the tests we’re planning to run on MICO
Stay tuned for the next blog post!