In this blog post we describe the efforts made to set up a machine-learning environment for discovering competence patterns from the text corpus obtained from the Zooniverse Snapshot Serengeti forum posts. We trained and compared Decision Trees (DT), Naive Bayes (NB), and K-nearest neighbors (KNN), to predict the competence level of users from their posts.
As a part of the implementation and integration of natural language processing (NLP) applications to the MICO cross-media analysis framework, previously, we applied and compared two sentiment analysis methods on the same data set. Of the two methods compared, one is lexicon-based and the other uses an RNTN (Recursive Neural Tensor Network) model. From a research perspective, using posts from Snapshot Serengeti is a potentially interesting idea as the texts we get from Snapshot Serengeti is highly characterized by descriptions of observed images rather than explicit opinions. Thus, studying sentiment analysis on such text as compared with the comments found in social media such as Facebook, creates its own new research challenges due to its unique features. The main result of our experiment is that the accuracy of the RNTN-based model exceeds that of the lexicon-based one by 17%.
In the task of running sentiment analysis on texts extracted the forum, our focus was assessing what the volunteers feel about the quality of the images. But now, we consider competence analysis as an advanced form of sentiment analysis by using the same data set. Here, we apply ML methods to exploit textual contents to detect and identify the competence of users. These methods have been effectively applied on the evaluation on students’ clinical notes.
To assess the level of expertise of the users, a majority vote scheme was applied as a ground truth to the classifications of each image. Depending on the number of correctly classified images carried out by individual users, a weight is assigned for each user as an overall performance using a rating scale from 0 (the least competent users) to 1 (the most competent users).
We used Rapidminer to process and to train the ML models. We ran a number of text tools on the annotated text corpus, such as tokenization, stemming, generating n-grams, extraction of number of tokens and extraction of aggregate tokens length. To evaluate the performance of each model, we applied a cross-validation technique. We have randomly split up the whole corpus into 70% training and 30% test set. Standard metrics (i.e their values range between 0 and 1), accuracy, precision, recall and F1, have been used to measure the performance of the models. The main results are summarized in the table below. As is shown in the table, DT outperforms the other two models NB, and KNN, by 16%, and 15% of accuracy respectively. We added more features to enhance the performance of the models and we achieved a significant increase of prediction accuracy with only the DT and KNN models.
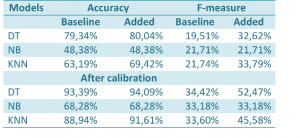
By calibrating the baseline scale, we were able to push the accuracy limit in the baseline models to 93%. All three models improved with the application of the calibration technique.
Yonas Demeke Woldemariam