This blog post is dedicated to the core components of the MICO system: the MICO extractors. They are doing all the hard multi-modal analysis work in the system. We previously wrote about how to configure and use the MICO extractor pipelines. In this post we will focus on what is going on inside the MICO system.
Extractors receive unstructured data input such as text, images, audio or video and generate structured RDF annotations out of it. By cleverly combining extractors within so called MICO pipelines we can generate cross-media annotations. Some of the extractors use their native intermediate annotation format which “annotation helper” extractors then convert to RDF. Other extractors directly produce RDF annotations, as shown in this image:
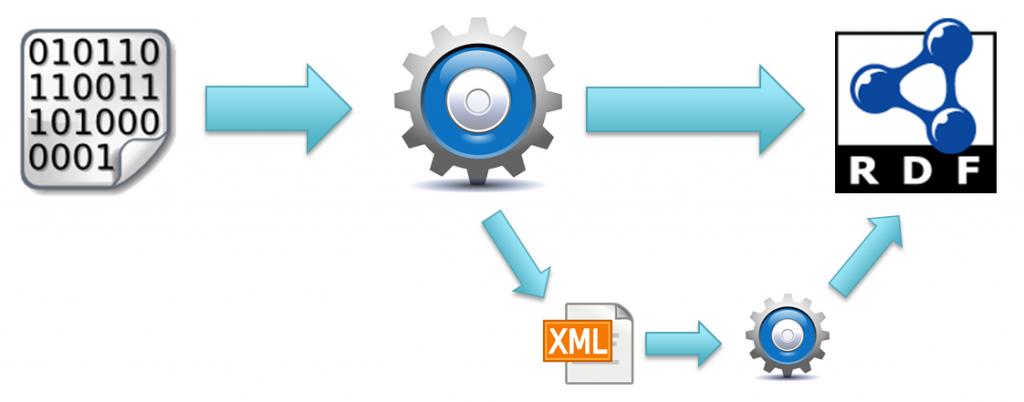
Mico extractor principle
Java or C++, that is the question!?
No, not really! Since the beginning of the project we opted to support both programming languages for extractor implementation within MICO. This makes the system pretty flexible in terms of close-to-hardware optimized implementations (C++), annotation support (Java, anno4j) and re-usability of existing libraries for multimedia analysis. To make the implementation of an extractor as easy as possible MICO provides easy-to-use APIs for literally everything an extractors is supposed to do:
- run time behavior
- event management
- persistence
- RDF annotations
- logging
Open Source
The MICO platform and the extractor APIs are Open Source Software (OSS) and licensed under the Apache License Version 2.0. . As for the MICO extractors, there is an “open business” approach: Many extractors are OSS (and will be released soon) while other are closed source commercial software(e.g. they have been brought into the project as so-called “background knowledge”). The modular, service based MICO system architecture makes it easy to develop, deploy and run both types of extractors.
We used a lot of existing open source software for extractor implementation (see Figure below). Thus MICO directly benefit from the scientific advances and improvements made within these popular OSS projects.

Open source software used in MICO extractors
Extractor Overview
The following table gives an overview of all extractor we’ve developed or plan to develop within the MICO project:
| Name | Version | Language | Purpose | License |
|---|---|---|---|---|
| Object & Animal Detection | 1.0.2 | C++ | annotation | ASL2.0 |
| Audio Demux | 1.0.1 | C++ | processing step | ASL2.0 / GPL |
| Face Detection | 1.0.3 | C++ | annotation | ASL2.0 / GPL |
| Diarization | 1.0.1 | Java | processing step | ASL2.0 |
| Kaldi2rdf | 1.0.1 | Java | annotation helper | ASL2.0 |
| Kaldi2txt | 1.0.0 | Java | processing step | ASL2.0 |
| Redlink Text Analysis | 1.0.0 | Java | annotation | ASL2.0 / Proprietary |
| ObjectDetection2RDF | 1.0.3 | Java | annotation helper | ASL2.0 |
| Speech-to-Text | 1.0.0 | C++ | annotation | ASL2.0 |
| Temporal Video Segmentation | 1.1.3 | C++ | annotation | Proprietary (FhG) |
| Media Quality | 1.0.1 | C++ | annotation | Proprietary (FhG) |
| Audio Editing Detection | 1.0.0 | C++ | annotation | Proprietary (FhG) |
| Media Info | 1.0.0 | C++ | annotation | ASL2.0 |
| MediaTags2rdf | 0.0.1 | Java | annotation helper | ASL2.0 |
| Speech-Music-Discrimination | 1.0.0 | C++ | annotation | Proprietary (FhG) |
| Generic Feature Extraction | planned | C++ | processing step | Proprietary (FhG) |
| Video Segment Matching | planned | C++ | annotation | Proprietary (FhG) |
| Stanford NLP | planned | Java | annotation | ASL2.0 / GPL |
| OpenNLP NER | planned | Java | annotation | ASL2.0 |
| OpenNLP Sentiment | planned | Java | annotation | ASL2.0 |
Orchestrating Extractors
MICO Pipelines are a combination of extractors in a graph like structure to be executed in a specific order to produce cross-media annotations. In order to have a first system ready by the start of the project we implemented a simple orchestration approach in our first MICO broker version. It used a simple mime type-based connections (i.e. string comparison) approach to register extractor processes, determine their dependencies, and to automatically configure pipelines based on these dependencies. However, this meant that all possible connections between all registered extractor processes were established, including unintended connections or even connections producing loops. Therefore, the approach had to be improved in order to support the following features:
- Standardized way of parameter specification passed to the extractor during start-up
- Means of pipeline configuration defining the extractors involved and their parameters
- End-User controlled start-up and shut-down of extractors establishing a pipeline for a specific purposes
We opted for an approach using a mixture of bash scripts and servlet configurations which is shown in the figure below. Every extractor deployed for the MICO system is obliged to support standard start-up and shut-down command line parameters. It also needs to be packaged with a short description bash script specifying the name, description and system (native, Java) it is running for. For easy changes and updates, the pipelines are configured in a separate Debian package. They specify the extractors to be loaded and the parameters to be passed in addition to the run/stop arguments.
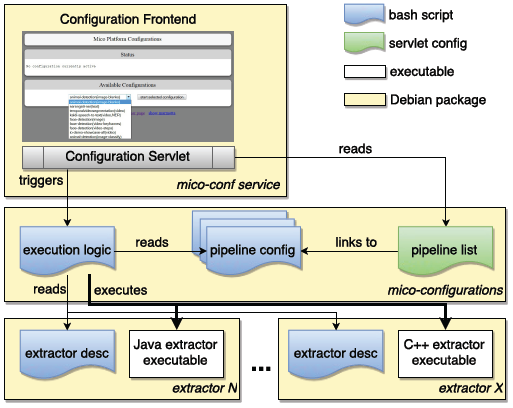
MICO extractor pipeline orchestration
However, this approach is still very limited, and one of the main priorities of year three of the project is to extend the extractor model and the implementation of the new broker. This will be described in future posts – stay tuned!
Pipelines
The extractors are pretty useless without extractor pipelines. Based on the selected MICO Showcases we created them at different levels of complexity.
For instance, the initial version of the Zooniverse pipeline to support image classification in Snapshot Seregenti, only required an animal detection task (it will soon be extended to also include textual analysis extractors):

MICO Zooniverse showcase pipeline for animal detection
In contrast, we designed a more complex pipeline for the InsideOut News Video showcase, which includes extraction from all kinds of media. We also provide parts of this pipeline (yellow and orange colored rectangles) as separate pipelines. The pipelines receives a video, segmenting them into shots, also extracting key frames and shot boundary images on which face detection is applied. In parallel, it separates the audio track from the video, uses ASR to derive text, and performs named entity recognition on the text. One can use the multitude of annotations of this pipeline, e.g. to do a query like: “Show me all video shot (video segmentation), where a person (face detection) in the video says (speech to text) about a specific topic (NER).”
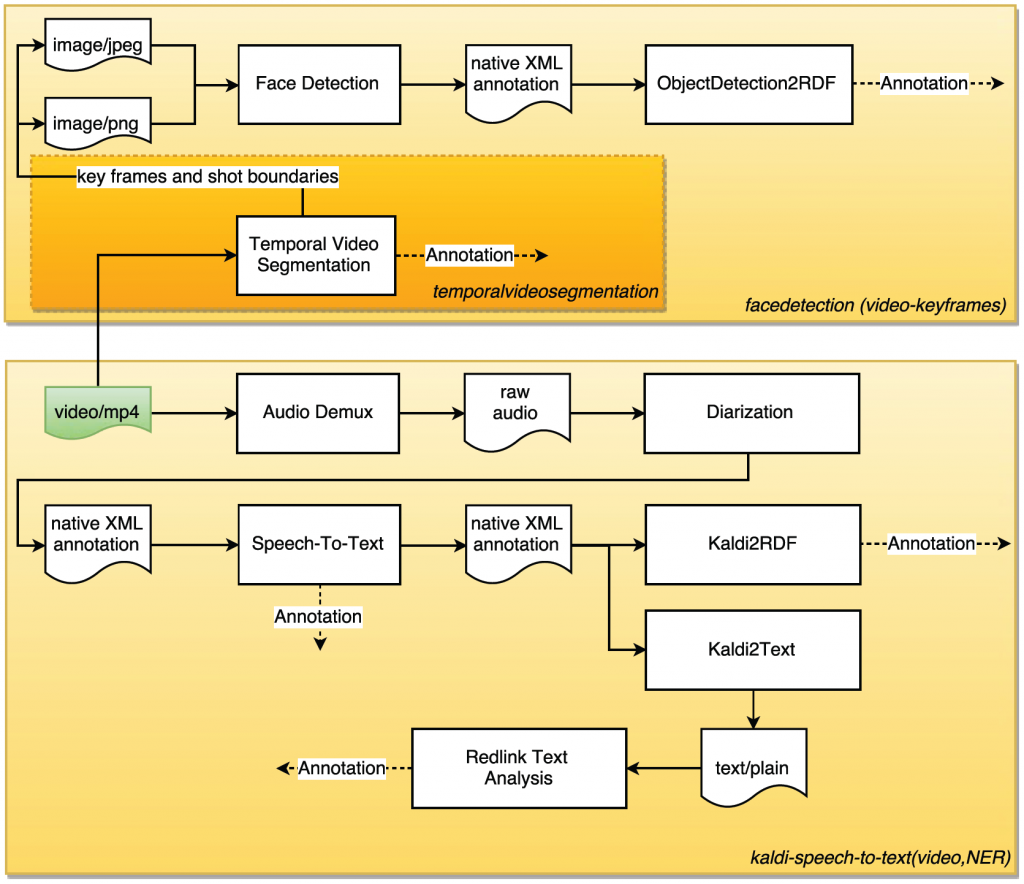
MICO InsideOut10 showcase pipelines and sub-pipelines
Highlights of today and challenges for the future
We are glad to already have a number of extractors (e.g. video segmentation, face detection), and pipelines available that are running relatively robust, fast and that are doing their job fairly well considering that most of the underlying algorithm and training models are used out-of-the-box. We are also happy that, at this stage of the project, a complete development and deployment process is in place.
However, some showcases have strong demands in terms of what an extractor should be able to do. The best example is the Zooniverse showcase in which we use our animal detection extractor on a very demanding data set. As a consequence, our first baseline implementation delivers bad results in terms of species detection performance, while doing ok for blank image detection (detailed blog post about results to be provided soon). While this underlines why citizen science crowdsourcing platforms such as Zooniverse are needed, we also feel challenged to improve our detection algorithms from an scientific point of view. Such research, and the inclusion of new extractors required for showcase demands regarding cross-media analysis, will be the focus of extractor work in the final year of the project.