Apache ManifoldCF
Central to our enterprise cross media search use case is the Apache Manifold Connectors Framework. ManifoldCF provides a set of pluggable connectors for connecting with different content repositories, indexing in different search servers and a crawler that can be run by scheduling jobs. Apache ManifoldCF is a top level Apache project which is originally contributed by MetaCarta Inc and currently well supported by open source community. There are three main types of connectors in ManifoldCF.
- Repository Connectors – Allows you to connect to content repositories for crawling purposes.
- Transformation Connectors – Allows you to modify content fetched from repositories before indexing into search servers. Currently provides a Tika connector for metadata extraction, OpenNLP connector for extracting named entities, Stanbol Connector and MetaData mapping connector that maps input fields to output fields.
- Output Connectors – Allows you to index documents, metadata and permissions in different search servers (indexes). Currently provide connectors for popular search servers such as Solr, Amazon CloudSearch and ElasticSearch.
MICO Transformation Connectors
We have implemented two transformation connectors for ManifoldCF, one for handling multimedia files such as videos and images and one for handling text documents. Connectors simply inject the content to MICO broker endpoint to extract metadata and store the results in the MICO Marmotta triple store. For each repository document, MICO connectors add the MICO content item URI as a metadata field. ManifoldCF connectors pipeline is given below.

Tika Connector guarantee that the downstream from connector is a text stream and the Metadata Adjuster maps input fields and extracted metadata fields to output document fields.
Build and Configure Connectors with ManifoldCF
Please follow the instruction given in README to build and configure MICO connectors.
Testing MCF-MICO Connectors
You can easily test the connector functionality by creating a simple job using FileSystem connector as the repository connector. Here we will show you the important steps for sample job configuration using FileSystem as repository connector and Solr as the output connector. For details on job configuration please refer the documentation.
- Setup the connectors pipeline as given below
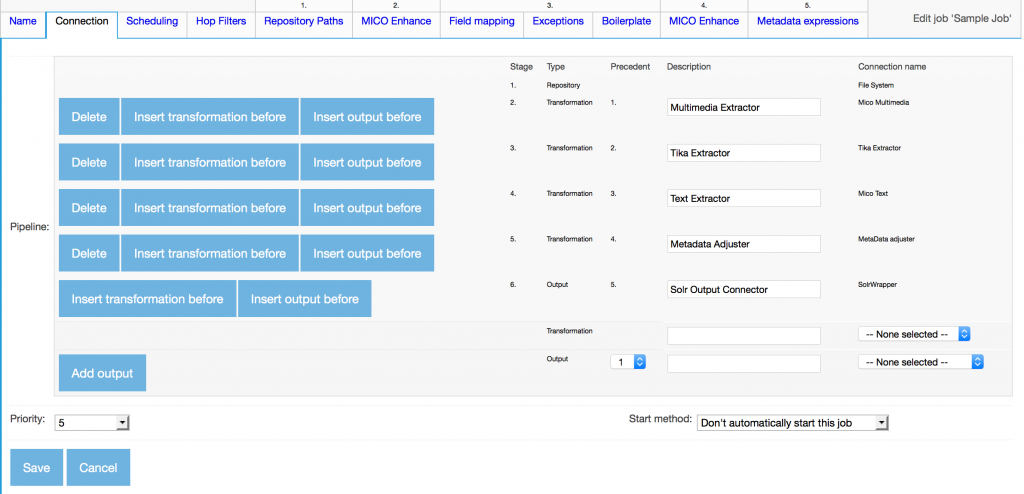
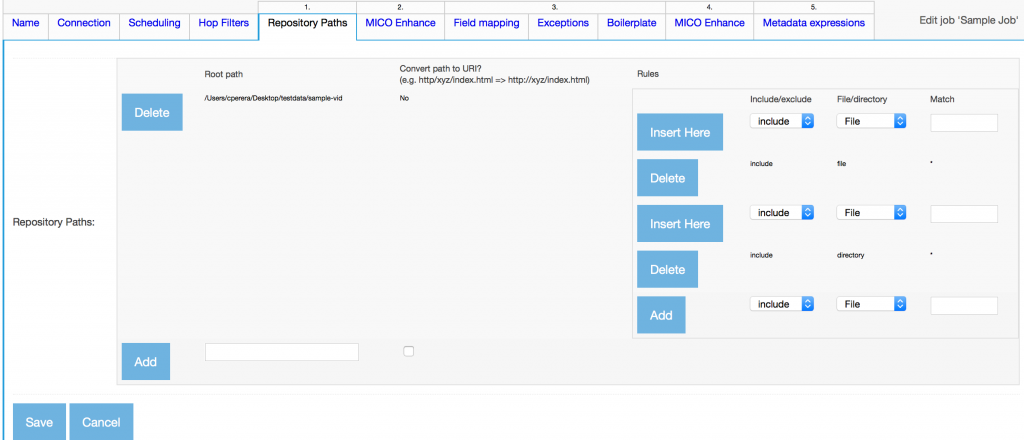
- Add repository path for documents to be indexed
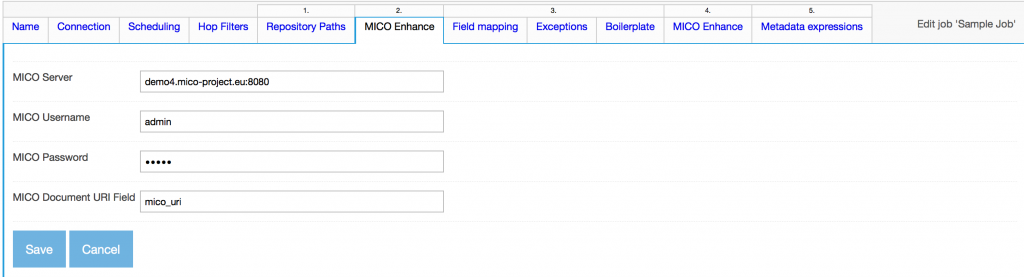
- Give MICO server configuration details and the field to attach content item uri
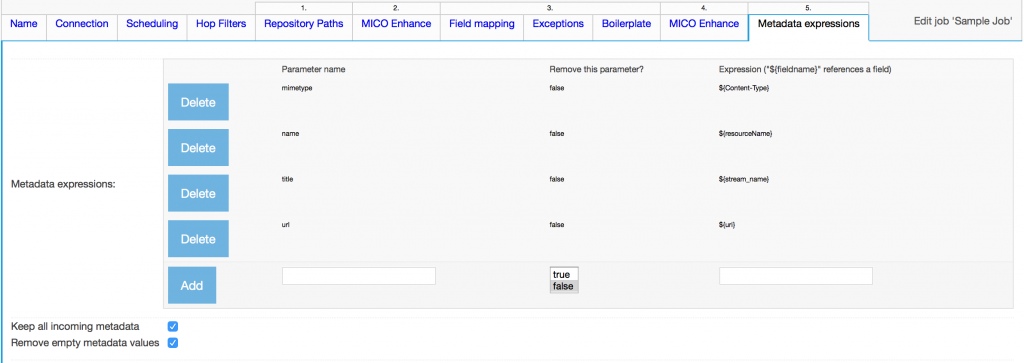
- Map input fields to Solr Schema fields as given below (your solr schema need to define fields in the right hand side)
We will keep you posted with final stages of the development in next few weeks. Please contact us for more details and any issues on our GitHub page for connectors.