Step 5 – Translate your XML annotations in RDF (~40 minutes) Step 5 – Realize that you must write several SPARQL queries by hand if you want to use the RDF repository (and get frightened)
NOTE: Deleted text means that we did it during the first integration attempt with the old platform versions, due to the limitations of the previous API. Don’t try this at home!
The last step for the successful integration of the AudioTrust+ project within the MICO platform, consisted of writing down a Java extractor, which could serve as “annotation helper”. The MICO extractor Java API is nearly identical to the C++ API and this of course was very helpful for us. Moreover, we already extended the Mico Metadata Model by creating our own AudioTamperingDetectionBody:
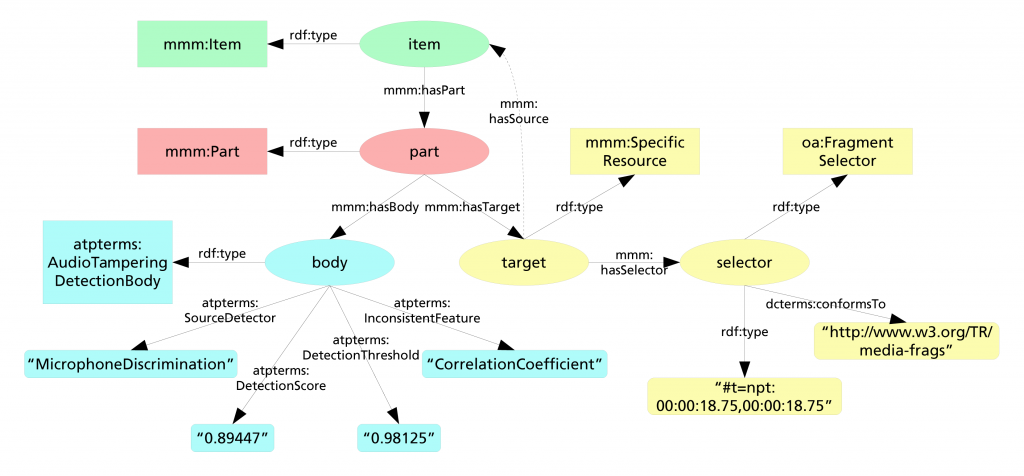
After parsing the XML annotation, translating it in RDF was straightfoward:
[code language=java]ObjectConnection con = ci.getObjectConnection();
//1. Read the output of the extractors, and produce rdf annotations accordingly
MicrophoneDiscrimination micClass = xmlData.getMicrophoneDiscrimination();
if(micClass != null){
List discs = micClass.getDiscontinuity();
if(discs!= null && !discs.isEmpty()){
for(MicrophoneDiscrimination.Discontinuity d : discs){
// Create a new content part for each element
Part oPart = ci.createPart(AnalysisServiceUtil.getServiceID(this));
oPart.addInput(inputXmlResource);
oPart.setSemanticType(“Single audio tampering detection”);
oPart.setSyntacticalType(ATPTERMS.AUDIO_TAMPERING_DETECTION_BODY);
// Create the corresponding body for the annotation
AudioTamperingDetectionBody body = createObject(con, AudioTamperingDetectionBody.class);
body.setSourceDetector(“MicrophoneDiscrimination”);
body.setInconsistentFeature(d.getSourceFeature());
body.setDetectionScore(d.getValue());
body.setDetectionThreshold(d.getThreshold());
// Specify the cutting location as a Temporal FragmentSelector
SpecificResource sr = createObject(con, SpecificResource.class);
try{
sr.setSource(((Part)inputXmlResource).getInputs().iterator().next().getRDFObject());
}
catch(NoSuchElementException e){
sr.setSource(inputXmlResource.getRDFObject());
}
String discontinuityTimestamp = micClass.getSegment().get(d.getSegmentId1()).getEnd().getValue();
FragmentSelector fragment = createObject(con, FragmentSelector.class);
fragment.setConformsTo(FragmentSpecification.W3C_MEDIA_FRAGMENTS.toString());
fragment.setValue(“#t=npt:”+discontinuityTimestamp+”,”+discontinuityTimestamp);
sr.setSelector(fragment);
oPart.setBody(body);
oPart.addTarget(sr);
response.sendNew(ci, oPart.getURI());
}
}
}[/code]
This was probably the nicest part of the whole integration process: We could easily setup the new annotations required by our use case, completely integrated within the MICO context, without any need for using RDF-specific syntax, nor SPARQL or LDPATH queries.
SPOILER ALERT:
During the next and final episode of the “MICO meets AudioTrust+” series, we are going to show how we managed to retrieve our annotations using the Apache Marmotta SPARQL query interface. Stay tuned!